Особенности построения адресов некоторых страниц Интернета
Особенности построения адресов некоторых страниц Интернета
Советуем разобраться в данном вопросе, поскольку это позволит лучше ориентироваться в Интернете, а также эффективно обходить проблемы, которые нередко возникают при попытке поставить некоторые страницы на мониторинг, с целью автоматического обнаружения изменений их содержания.
Нередко ресурс может включать одновременно и элементы видимого, и невидимого Интернета.
Иногда веб-мастера принимают меры к тому, чтобы заведомо исключить попадание своего сайта в разряд невидимых, с точки зрения некоторых поисковых машин, сохранив при этом ресурс удобным в использовании и внешне привлекательным для пользователей. Для этого в ряде случаев сайты, написанные, например, на Flash, имеют HTML-копии. Такие копии называют «зеркалами» страницы, они позволяют увидеть ее содержимое с помощью тех информационных систем, которые имеют какие-то затруднения в работе с форматом основного варианта сайта.
Прямой и непрямой URL. Динамические страницы.Еще недавно в специальной литературе, изданной за рубежом, говорилось о том, что страницы, имеющие непрямой URL, как правило, относятся к невидимому Интернету.
Сегодня ресурсы с непрямым адресом могут нормально индексироваться поисковыми машинами. Однако попытки специалистов конкурентной разведки поставить их на мониторинг могут натолкнуться на неожиданную проблему, которая, тем не менее, может быть преодолена.
Если адрес страницы состоит только из букв, цифр и косых черточек, то это прямой url страницы, которая относится, как правило, к видимому Интернету.
Примеры прямого URL: http://www.yandex.ru/; http://yushchuk.livejournal.com/35905.html.
Сложнее обстоит дело со страницами, где в адресе встречается вопросительный знак, после которого следует множество непонятных неподготовленному человеку символов. Обычно все, что расположено левее вопросительного знака, приведет вас на страницу с формой, требующей заполнения или просто на одну из первых страниц сайта, а вот правее вопросительного знака часто записана информация, описывающая запрос.
В качестве примера приведем адрес страницы, которая показывает результаты по запросу «маркетинг» в Яндексе: http://www.yandex.ru/yandsearch?text=%EC%E0%F0%EA%E5%F2%E8%ED%E3&stype=www.
К этому адресу мы обратились для того, чтобы с его помощью разобраться в способах решения типичной проблемы. Поэтому чуть позже мы к нему вернемся.
Непосредственно в этой правой части адреса страницы может содержаться описание критериев запроса – и тогда вы попадете на страницу еще раз, введя этот адрес в адресную строку браузера. А может запрос там и не содержаться, и тогда вам не удастся повторить переход на нужную страницу, введя адрес такой страницы в адресную строку браузера. В этом втором случае попытка перейти по адресу страницы приводит к загрузке незаполненного шаблона.
Рассмотрим два примера, когда запросы одинаковы, но сайты устроены по-разному, что приводит к разным результатам.
Итак, для наглядности поищем людей, которые разместили свои резюме в регионе «Екатеринбург» на сайтах Superjob.ru и e1.ru, причем анкеты их должны содержать слово «повар». При этом, заполняя формы запроса, мы намеренно не будем указывать никаких ограничений по полу, возрасту, образованию и прочим параметрам, дабы это не привело к возникновению дополнительных переменных величин поиска.
Вот адрес страницы, выдаваемой в ответ на запрос, на сайте Superjob.ru:
http://e-burg.superjob.ru/resume/search_resume.html?submit=1&period=60&town=33&paymentfrom=&paymentto=&type=0&old1=&old2=&pol=0&maritalstatus=0&children=0&education=0&language=1&lang_level=0&stazhyear=0&keywords=%EF%EE%E2%E0%F0&kwc=or&rating=0&tree_keyword=&saveparam=1.(ТЕКСТ В ОДНУ СТРОКУ.СТРОКУ РАЗБИТЬ ПО ШИРИНЕ ПОЛОСЫ)
В приведенной выше строке адреса описаны город (он имеет номер 33 по классификатору сайта и отражен в символах «town=33», а также слово «повар», на кодировке которого мы пока не будем останавливаться подробно). Если скопировать этот адрес в поисковую строку браузера, то можно вновь получить страницу с информацией о людях с требуемыми параметрами, как если бы мы ввели ее с клавиатуры заново.
Вид страницы по этому запросу приведен на рис. 3.
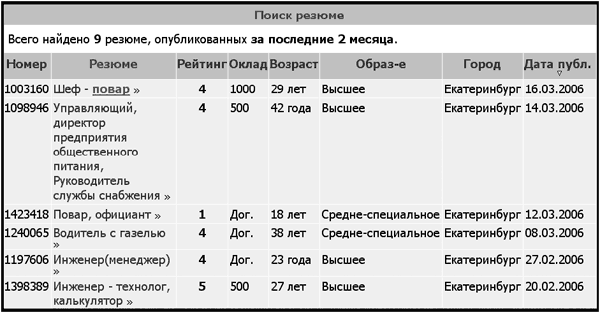
Рис. 3. Результат запроса на сайт Superjob.ru в поисках повара в Екатеринбурге.
Вот ответ на такой же запрос с сайта e1.ru при тех же критериях поиска был получен результат, отображенный на рис. 4.
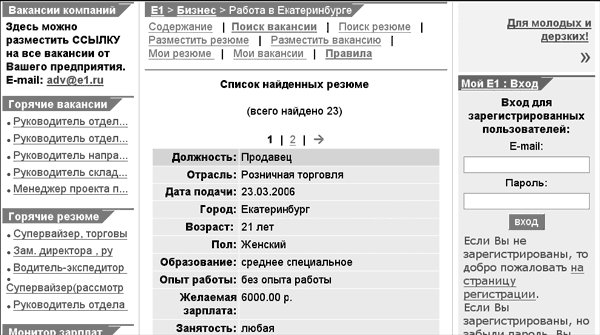
Рис. 4. Результат запроса на сайт e1.ru в поисках повара в Екатеринбурге.
Адрес страницы, показанной на рис. 4, выглядит следующим образом: http:// www.e1.ru/business/job/resume.search.php.
Не нужно быть в высшей степени сведущим относительно всех премудростей Интернета, чтобы заметить: адрес этот выглядит гораздо короче предыдущего. Кроме того, в нем отсутствует описание запроса. Попытка перейти повторно на нужную страницу, просто введя в поисковую строку браузера вышеуказанные координаты, как раз и приводит к незаполненной форме.
Связано такое положение вещей с тем, что в принципе существует два типа запросов – так называемые GET и POST.
При запросе типа GET параметры поиска указаны в адресной строке, поэтому переход по такому адресу приводит на нужную страницу (этот запрос выглядит как достаточно длинная строка с множеством символов, в том числе знаком «%» или с большим количеством англоязычных слов).
Метод POST не подразумевает передачу параметров поиска через адресную строку. Данные о запросе передаются отдельно, по служебным каналам и не могут быть просмотрены обычным пользователем.
Тем не менее, часто и в такой ситуации можно найти решение. Если на странице, которая изображена на рис. 8, перейти по ссылке на вторую страницу результатов запроса (кликнув мышкой по цифре «2» в перечне страниц), то адрес этой второй страницы будет содержать параметры поиска: http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EF%EE%E2%E0%F0+%EE%F4%E8%F6%E8%E0%ED%F2&search_by=1&show_for=7&order_by=2&search=yes&page=1.
Видно, что адрес стал длинным, и в нем появилось множество символов, которых не было вначале. Интересно, что если после этого кликнуть по ссылке первой страницы и именно таким путем вернуться на первую страницу, то у нее также появится адрес, содержащий описание самого запроса и позволяющий при вводе его в адресную строку браузера попадать непосредственно на эту первую страницу: http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EF%EE%E2%E0%F0+%EE%F4%E8%F6%E8%E0%ED%F2&search_by=1&show_for=7&order_by=2&search=yes&page=0.
Мы приводим эти, на первый взгляд, абстрактные для гуманитариев закорючки не из любви к теории. Практическое значение подобного явления становится понятно, когда возникает необходимость поставить на мониторинг страницы сайта, имеющего подобные алгоритмы работы. Ведь этот «длинный» адрес первой страницы, полученный путем перехода на вторую страницу и возврата с нее обратно на первую, можно поставить на мониторинг.
Казалось бы, проблема решена. Но и тут не исключены сложности. Хорошо, когда можно перейти с первой страницы на вторую, а затем вернуться. Однако по некоторым запросам страница бывает всего одна, поэтому перейти с нее просто некуда. Выход и в таком случае есть. Правда, он несколько сложнее тех решений, о которых речь шла выше. Предлагаем рассмотреть данный вопрос более подробно, поскольку соответствующей литературой, как нам кажется, он пока еще специально не освещался. А кроме того, научиться ставить подобные сложные страницы на мониторинг отнюдь не помешает – это очень экономит время. Предлагаемое решение разработано нами совместно с участниками форума на сайте e1.ru в Екатеринбурге и со слушателями нашего курса «Маркетинг рисков и возможностей: конкурентная разведка». Итак, постараемся максимально доступно изложить весь алгоритм действий, чтобы он был понятен как можно более широкому кругу пользователей.
Для того чтобы решить проблему постановки на автоматический мониторинг страниц, которые выдаются в ответ на запрос в единственном экземпляре, следует обратиться к базе данных таким образом, чтобы можно было заведомо рассчитывать на результат, состоящий из более чем одного ресурса. Применительно к сайтам вакансий и резюме это должны быть массовые специальности. Зададим поиск по признаку (по ключевому слову) «Менеджер» на странице поиска резюме на сайте e1.ru (рис. 5).

Рис 5. Введен запрос по слову «Менеджер» в форме поиска резюме не сайте e1.tif.
Получив результат – первую страницу, мы точно так же, как в предыдущем случае, перейдем на вторую, кликнув по ссылке с номером страницы «2». Ее адрес (URL) выглядит так: http://www.e1.ru/business/job/resume.search.php?sex=l&key_words=%EC%E5%ED%E5%E4%E6%E5%F0&search_by=1&show_for=7&order_by=2&search=yes&page=1.
Затем вновь вернемся на первую страницу, точно так же кликнув по ссылке страницы «1». После этого, как мы говорили ранее, в браузер будет загружена первая страница, полученная возвратом со второй. Ее URL выглядит следующим образом (это реальный адрес): http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EC%E5%ED%E5%E4%E6%E5%F0&search_by=1&show_for=7&order_by=2&search=yes&page=0.
Сравните адреса первой и второй страниц. Видно, что они почти идентичны, за исключением последнего знака: вторая страница в конце адреса содержит цифру «1», а первая – цифру «0». Кстати, заметим, что третья страница будет оканчиваться на «2» – это подтверждено экспериментально.
Теперь обратите, пожалуйста, внимание на сам набор символов: «%EC%E5%ED%E5%E4%E6%E5%F0».
Он начинается после знака «=» и заканчивается перед знаком «&». Этот перечень и представляет собой слово «Менеджер», написанное в определенной кодировке. В данном случае нам неважно, как она называется, гораздо существеннее то, что это стандартная кодировка, которая применяется во всех системах. Если же кому-то из читателей это все-таки интересно, то сообщаем, что именуется она не иначе как UrlEncode, а то, что стоит после знака процента, – код символа в UTF-8.
Научившись разбираться во всех приведенных нюансах, вы сможете автоматизировать процесс создания набора символов для подобных сложных страниц. Причем изучать кодировки для этого совершенно не требуется.
Проведем простейший эксперимент: наберем в поисковой строке Яндекса слово «Manager», а в отдельном запросе – слово «Менеджер» и сравним URL’ы страниц, которые будут получены в ответ.
Итак, адрес страницы по англоязычному запросу «Manager» выглядит следующим образом:
http://www.yandex.ru/yandsearch?stype=www&nl=0&text=Manager.
А вот так выглядит URL ресурса по русскоязычному запросу «Менеджер»:
http://www.yandex.ru/yandsearch?text=%EC%E5%ED%E5%E4%E6%E5%F0&stype=www.
Очевидно, что кодированные тексты в запросе резюме на сайте e1 и на Яндексе по слову «менеджер» идентичны и имеют вид
«%EC%E5%ED%E5%E4%E6%E5%F0».
Мы уже располагаем примером синтаксиса строки страницы номер один с сайта e1 по запросу «менеджер»:
http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%EC%E5%ED%E5%E4%E6%E5%F0&search_by=1&show_for=7&order_by=2&search=yes&page=0.
Можно произвольно подставлять любое нужное слово, предварительно получая его закодированное написание в Яндексе, и таким образом принудительно генерировать на сайте e1 и ему подобных ресурсах нужные страницы с нужным форматом адреса, который впоследствии технически можно ставить на автоматический мониторинг.
Проверим это утверждение на примере запроса по ключевому слову «Автоленд».
Написание слова «Автоленд» в URL’е, полученное с помощью запроса в Яндексе, выглядит так:
«%C0%E2%F2%EE%EB%E5%ED%E4».
Если механически подставить это значение в строку запроса по поиску вакансий на сайте e1 для первой страницы выдачи, то адрес будет выглядеть следующим образом:
http://www.e1.ru/business/job/resume.search.php?sex=l&keywords=%C0%E2%F2%EE%EB%E5%ED%E4&search_by=1&show_for=7&order_by=2&search=yes&page=0.
Подставив эти координаты в адресную строку браузера, мы получили всего одну страницу, на которой содержалось резюме конкретного специалиста. В тексте этого документа была информация о том, что человек действительно работал когда-то в компании «Автоленд».
Однако помимо всего описанного выше, долгое время существовала еще проблема индексации динамически генерируемых страниц, которая относила их к невидимому Интернету.
Динамические страницы – это ресурсы, создаваемые небольшой программой – скриптом – в момент запроса браузера к серверу. Такая страница часто имеет вид:
aaaa?b=x&c=y
где aaaa – название скрипта, а после «?» идут параметры, включенные в запрос. Обычно динамические страницы определяются пауком на том основании, что они содержат символы
«?», «&» и «=«в URL.
Большинство поисковых систем до недавнего времени старались обходить такие страницы стороной, т. к. паук вполне мог на них «зависнуть» навсегда, в силу технических причин – потому что он непрерывно пытался посетить несуществующие страницы, адреса которых практически до бесконечности может генерировать скрипт.
Динамические страницы очень удобны для производства сайтов, и игнорировать их было бы недальновидно. Поэтому в последнее время крупнейшие поисковые системы стали одна за другой объявлять о том, что они начинают индексировать такие ресурсы, так что сайтов, которые относились прежде к невидимому Интернету в силу того, что содержали динамические страницы, стало меньше.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 1 Правила построения HTML-страниц
Глава 1 Правила построения HTML-страниц 1.1. Общие понятия HTML1.2. Структура HTML-документаДля создания веб-страниц часто используется язык гипертекстовой разметки HTML. Конечно, каждый сайт индивидуален, но существуют общие правила построения HTML-страниц. Им обязательно нужно
Автоматизация некоторых действий с помощью Мастеров
Автоматизация некоторых действий с помощью Мастеров Как мы уже могли убедиться, процесс создания веб-страниц в программе CatsHtml довольно прост: нужно лишь грамотно пользоваться соответствующими инструментами, и при необходимости вручную вносить требуемые корректировки
Последовательности страниц и нумерация страниц
Последовательности страниц и нумерация страниц Пока я использовал один и тот же шаблон страницы для всех страниц в рассмотренных нами документах XSL-FO. Если содержимое документа занимает более одной страницы, процессор XSL-FO использует тот же шаблон страницы для всех
О некоторых опциях команды zpool
О некоторых опциях команды zpool Команда zpool поддерживает ещё множество субкоманд, предназначенных для экспорта и импорта пула, добавления к нему устройств и изъятия оных, и так далее. Но сейчас я расскажу о некоторых опциях, которые могут оказаться необходимыми при
Особенности создания Web-страниц
Особенности создания Web-страниц Некоторые Web-дизайнеры стараются в полной мере использовать возможности, предусмотренные спецификацией HTML, и создают HTML-документы, напоминающие страницы печатных изданий. Однако использование расширенных средств HTML может стать
§ 121. Об употреблении некоторых топонимов
§ 121. Об употреблении некоторых топонимов 20 ноября 2005По-русски правильно писать Таллин (а не Таллинн), Алма-Ата (а не Алматы), Белоруссия (Беларусь — это трактор), поехать на Украину (а не в Украину), независимо от того, что думают по этому поводу жители указанных
Пошаговый алгоритм построения очереди клиентов из Интернета
Пошаговый алгоритм построения очереди клиентов из Интернета Для того чтобы получить регулярный поток клиентов из Интернета, необходимо выполнить следующие шаги (каждый из которых подробно описан в книге):1. Подготовьте свой бизнес к продвижению в Интернете.• Составьте
Использование некоторых ключей реестра
Использование некоторых ключей реестра Добавление элементов в контекстное меню "Создать"1. Создать новый документ, поместить его в папку Windows/ShellNew2. В редакторе реестра найти расширение этого файла, добавить новый подключ, добавить туда строку: FileName в качестве значения
ПРИЛОЖЕНИЕ Г Решения некоторых упражнений
ПРИЛОЖЕНИЕ Г Решения некоторых упражнений Глава 1 1. В обоих процессах нужно лишь указать флаг O_APPEND при вызове функции open или режим дополнения файла при вызове fopen. Ядро гарантирует, что данные будут дописываться в конец файла. Это самая простая форма синхронизации
О некоторых настройках Excel
О некоторых настройках Excel В процессе работы мы неоднократно обращались к диалоговому окну Параметры Excel. Напомним, что данное диалоговое окно вызывают кнопкой Параметры Excel в меню Кнопки «Office».Диалоговое окно Параметры Excel содержит несколько категорий, которые выбирают
Блокировка некоторых возможностей
Блокировка некоторых возможностей Рассмотрим в данном разделе некоторые параметры реестра, с помощью которых можно заблокировать те или иные поля окна, вызываемого командой Сервис ? Параметры.• Вкладка Уведомления, флажок Запрашивать уведомления о прочтении для всех
О некоторых опциях команды zpool
О некоторых опциях команды zpool Команда zpool поддерживает ещё множество субкоманд, предназначенных для экспорта и импорта пула, добавления к нему устройств и изъятия оных, и так далее. Но сейчас я расскажу о некоторых опциях, которые могут оказаться необходимыми при
Подключение некоторых кабелей
Подключение некоторых кабелей Снимите крышку корпуса, открутив крепежные винты.Перед тем как закреплять материнскую плату внутри корпуса, подсоедините к ней провода, которые идут от индикаторов на передней панели, от кнопок Reset и Power, а также от динамика (многие
Особенности просмотра WAP-страниц
Особенности просмотра WAP-страниц Все мы привыкли при просмотре вебсайтов пользоваться мышью (или ее аналогами) и не представляем, как можно обойтись без нее. Само собой, создатели протокола WAP предусмотрели, чтобы «путешествие» в Сети с мобильных устройств, не имеющих
Глава 4 Самостоятельная диагностика некоторых неисправностей
Глава 4 Самостоятельная диагностика некоторых неисправностей Довольно часто неопытных пользователей «разводят» на новые комплектующие, например заявляют, что «винт посыпался», хотя на самом деле можно было пометить все «битые» секторы (если они вообще есть) и дальше