Построение матрицы операторного предшествования
Построение множеств крайних правых и крайних левых символов
Построение множеств крайних левых и крайних правых символов выполним согласно описанному ранее алгоритму.
На первом шаге возьмем все крайние левые и крайние правые символы из правил грамматики G. Получим множества, представленные в табл. 3.2.
Таблица 3.2. Множества крайних левых и крайних правых символов. Шаг 1
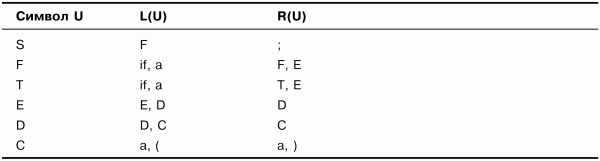
Из табл. 3.2 видно, что множества L(U) для символов S, Е, D, а также множества R(U) для символов F, Т, Е, D содержат другие нетерминальные символы, а потому должны быть дополнены. Например, L(S) должно быть дополнено L(F), так как символ F входит в L(S): F е L(S), а R(F) должно быть дополнено R(E), так как символ Е входит в R(F): Е е R(F).
Выполним необходимые дополнения и получим множества, представленные в табл. 3.3.
Таблица 3.3. Множества крайних левых и крайних правых символов. Шаг 2
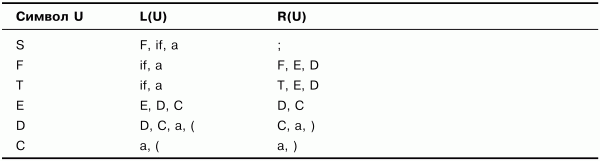
Практически все множества в табл. 3.3 изменились по сравнению с табл. 3.2 (кроме множеств для символа С), а значит, построение не закончено. Продолжим дополнять множества. Получим множества, представленные в табл. 3.4.
В табл. 3.4 по сравнению с табл. 3.3 изменились множества для символов F, Г и Е – построение не закончено. Продолжим дополнять множества. Получим множества, представленные в табл. 3.5.
Таблица 3.4. Множества крайних левых и крайних правых символов. Шаг 3
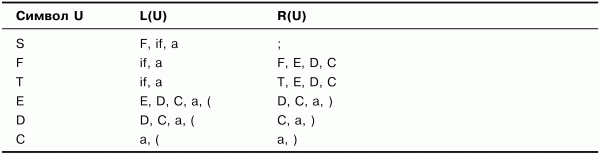
Таблица 3.5. Множества крайних левых и крайних правых символов. Шаг 4 (результат)
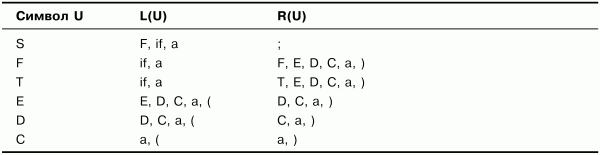
В табл. 3.5 по сравнению с табл. 3.4 изменились только множества R(U) для символов F иT– построение не закончено. Продолжим дополнять множества. Но если выполнить еще один шаг (шаг 5), то можно убедиться, что множества уже больше не изменятся (чтобы не создавать еще одну лишнюю таблицу, этот шаг здесь выполнять не будем). Таким образом, множества, представленные в табл. 3.5, являются результатом построения множеств крайних левых и крайних правых символов грамматики G.
Построение множеств крайних правых и крайних левых терминальных символов
Построение множеств крайних левых и крайних правых терминальных символов также выполним согласно описанному выше алгоритму.
На первом шаге возьмем все крайние левые и крайние правые терминальные символы из правил грамматики G. Получим множества, представленные в табл. 3.6.
Таблица 3.6. Множества крайних левых и крайних правых терминальных символов. Шаг 1

Дополним множества, представленные в табл. 3.6, на основании ранее построенных множеств крайних левых и крайних правых символов, представленных в табл. 3.5. Например, Lt(Е) должно быть дополнено Lt(D) и Lt(C), так как символы D и C входят в L(E): D, С e L(E), а Rt(F) должно быть дополнено Rt(E), Rt(D) и Rt(C), так как символы E, D и С входят в R(F): E, D, С е R(F).
Получим итоговые множества крайних левых и крайних правых терминальных символов, которые представлены в табл. 3.7.
Таблица 3.7. Множества крайних левых и крайних правых терминальных символов. Результат

Теперь все готово для заполнения матрицы операторного предшествования.
Заполнение матрицы предшествования
Для заполнения матрицы операторного предшествования необходимы множества крайних левых и крайних правых терминальных символов, представленные в табл. 3.7, и правила исходной грамматики G.
Заполнение таблицы рассмотрим на примере лексем or и (.
Символ or не стоит рядом с другими терминальными символами в правилах грамматики. Поэтому знак «=.» («составляет основу») для него не используется. Символ or стоит слева от нетерминального символа D в правиле Е ? Е or D. В множество Lt(D) входят символы and, а и (. Поэтому в строке матрицы, помеченной символом or, ставим знак «<.» («предшествует») в клетках на пересечении со столбцами, помеченными символами and, а и (.
Кроме того, символ or стоит справа от нетерминального символа Е в том же правиле Е ? Е or D. В множество Rt(E) входят символы or, xor, and, а и). Поэтому в столбце матрицы, помеченном символом or, ставим знак «.>» («следует») в клетках на пересечении со строками, помеченными символами or, xor, and, а и).
Больше ни в каких правилах символ or не встречается, поэтому заполнение матрицы для него закончено.
Символ (стоит рядом с терминальным символом) в правиле С ? (Е) (между ними должно быть не более одного нетерминального символа – в данном случае один символ Е). Поэтому в строке матрицы, помеченной символом (, ставим знак «=.» («составляет основу») на пересечении со столбцом, помеченным символом).
Символ (также стоит слева от нетерминального символа Е в том же правиле С ? (Е). В множество Lt(E) входят символы or, xor, and, а и (. Поэтому в строке матрицы, помеченной символом (, ставим знак «<.» («предшествует») в клетках на пересечении со столбцами, помеченными символами or, xor, and, а и (.
Больше ни в каких правилах символ (не встречается, поэтому заполнение матрицы для него закончено.
Повторяя описанные выше действия по заполнению матрицы для всех терминальных символов грамматики G, получим матрицу операторного предшествования. Останется только заполнить строку, соответствующую символу «начало строки», и столбец, соответствующий символу «конец строки».
Начальным символом грамматики G является символ S, поэтому для заполнения строки, помеченной ?н, возьмем множество Lt(S). В это множество входят символы if, а и;. Поэтому в строке матрицы, помеченной символом ?н, ставим знак «<.» («предшествует») в клетках на пересечении со столбцами, помеченными символами if, а и;.
Аналогично, для заполнения столбца, помеченного ?к, возьмем множество R^(S). В это множество входит только один символ —;. Поэтому в столбце матрицы, помеченном символом ?к, ставим знак «.>» («следует») в клетке на пересечении со строкой, помеченной символом;.
В итоге получим заполненную матрицу операторного предшествования, которая представлена в табл. 3.8.
Таблица 3.8. Матрица операторного предшествования

Теперь на основе исходной грамматики G можно построить остовную грамматику G'({if,then,else,a,=,or,xor,and,(,),},{E},P',E) с правилами P':
E ? E; – правило 1;
E ? if E then E else E | if E then E | a:= E – правила 2, 3 и 4;
E ? if E then E else E | a:= E – правила 5 и 6;
E ? E or E | E xor E | E – правила 7, 8 и 9;
E ? E and E | E – правила 10 и 11;
E ? a | (E) – правила 12 и 13.
Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
Всего имеем 13 правил грамматики. Причем правила 2 и 5, а также правила 4 и 6 в остовной грамматике неразличимы, а правила 9 и 11 не имеют смысла (как было уже сказано, цепные правила в остовных грамматиках теряют смысл). То, что две пары правил стали неразличимы, не имеет значения, так как по смыслу (семантике входного языка) эти две пары правил обозначают одно и то же (правила 2 и 5 соответствуют полному условному оператору, а правила 9 и 11 – оператору присваивания). Поэтому в дереве синтаксического разбора нет необходимости их различать. Следовательно, синтаксический распознаватель может пользоваться остовной грамматикой G'.
Примеры выполнения разбора предложений входного языка
Рассмотрим примеры разбора цепочек входного языка в виде последовательности конфигураций МП-автомата, выполняющего разбор. Результат разбора будем представлять в виде последовательности номеров правил грамматики. На основе найденной последовательности правил после выполнения разбора при отсутствии ошибок (когда входная цепочка принята МП-автоматом) можно построить дерево синтаксического разбора.
Рассматриваемый МП-автомат имеет только одно состояние. Тогда для иллюстрации работы МП-автомата будем записывать каждую его конфигурацию в виде трех составляющих {?|?|?}, где:
• ? – непрочитанная часть входной цепочки;
• ? – содержимое стека МП-автомата;
• ? – последовательность номеров примененных правил.
В начальном состоянии вся входная цепочка не прочитана, стек автомата содержит только лексему типа «начало строки», последовательность номеров правил пуста.
Для удобства чтения стек МП-автомата будем заполнять в порядке справа налево, тогда находящимся на верхушке стека будет считаться крайний правый символ в цепочке ?.
Пример 1
Возьмем входную цепочку «if a or b and c then a:= 1 xor c;».
После выполнения лексического анализа, если все лексемы типа «идентификатор» и «константа» обозначить как «a», получим цепочку: «if a or a and a then a:= a xor a;».
Рассмотрим процесс синтаксического анализа этой входной цепочки. Шаги функционирования МП-автомата будем обозначать символом «?». Символом «?п» будем обозначать шаги, на которых выполняется сдвиг (перенос), символом «?с» – шаги, на которых выполняется свертка.
{if a or a and a then a := a xor a;?к|?н |л} ч п
{a or a and a then a := a xor a;?к|?н if|л} ч п
{or a and a then a := a xor a;?к|?н if a|л} ч с
{or a and a then a := a xor a;?к|?н if E|12} ч п
{a and a then a := a xor a;?к|?н if E or|12} ч п
{and a then a := a xor a;?к|?н if E or a|12} ? с
{and a then a := a xor a;?к|?н if E or E|12 12} ? п
{a then a := a xor a;?к|?н if E or E and|12 12} ? п
{then a := a xor a;?к|?н if E or E and a|12 12} ? с
{then a := a xor a;?к|?н if E or E and E|12 12 12} ? с
{then a := a xor a;?к|?н if E or E|12 12 12 10} ? с
{then a := a xor a;?к|?н if E|12 12 12 10 7} ? п
{a := a xor a;?к|?н if E then|12 12 12 10 7} ч п
{:= a xor a;?к|?н if E then a|12 12 12 10 7} ч п
{a xor a;?к|?н if E then a :=|12 12 12 10 7} ч п
{xor a;?к|?н if E then a := a|12 12 12 10 7} ч с
{xor a;?к|?н if E then a := E|12 12 12 10 7 12} ч п
{a;?к|?н if E then a := E xor|12 12 12 10 7 12} ч п
{;?к|?н if E then a := E xor a|12 12 12 10 7 12} ч с
{;?к|?н if E then a:= E xor E|12 12 12 10 7 12} ? с
{;?к|?н if E then a := E|12 12 12 10 7 12 12 8} ? с
{;?к|?н if E then E|12 12 12 10 7 12 12 8 4} ? с
{;?к|?н E|12 12 12 10 7 12 12 8 4 3} ? п
{?к|?н E;|12 12 12 10 7 12 12 8 4 3} ? с
{?к|E?н |12 12 12 10 7 12 12 8 4 3 1}– разбор закончен, МП-автомат перешел в конечную конфигурацию, цепочка принята.
В результате получим последовательность правил: 12 12 12 107 12 12843 1. Этой последовательности правил будет соответствовать цепочка вывода на основе остовной грамматики С:
E?1 E; ?3 if E then E; ?4 if E then a := E; ?8 if E then a := E xor E; ?12 if E then a := E xor a; ?12 if E then a := a xor a; ?7 if E or E then a:= a xor a; ?10 if E or E and E then a := a xor a; ?12 if E or E and a then a := a xor a; ?12 if E or a and a then a := a xor a; ?12 if a or a and a then a := a xor a;
Стоит обратить внимание, что, так как данный МП-автомат строит правосторонний вывод, в цепочке вывода на каждом шаге правило всегда применяется к крайнему правому нетерминальному символу в цепочке.
Дерево синтаксического разбора, соответствующее данной входной цепочке, приведено на рис. 3.2.
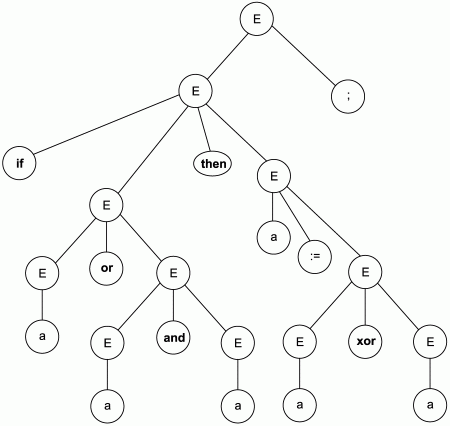
Рис. 3.2. Дерево синтаксического разбора входной цепочки «if a or a and a then а:= а хог а;».
Пример 2
Возьмем входную цепочку «if {a or b then а:= 25;».
После выполнения лексического анализа, если все лексемы типа «идентификатор» и «константа» обозначить как «а», получим цепочку: «if (a or a then а:= а».
Рассмотрим процесс синтаксического анализа этой входной цепочки:
{if (a or a then a := a;?к|?н |?} ? п
{(a or a then a := a;?к|?н if|?} ? п
{a or a then a := a;?к|?н if(|?} ? п
{or a then a := a;?к|?н if(a|?} ? с
{or a then a := a;?к|?н if(E|12} ? п
{a then a := a;?к|?н if(E or|12} ? п
{then a := a;?к|?н if(E or a|12} ? с
{then a := a;?к|?н if(E or E|12 12} ? с
{then a := a;?к|?н if(E|12 12 7} – нет отношения предшествования между лексемами «(» и «then», разбор закончен, МП-автомат не перешел в конечную конфигурацию, цепочка не принята (выдается сообщение об ошибке).
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК