Собственные данные потока
Собственные данные потока
Описанной выше схеме общих данных приложения и локальных данных потока, достаточных для большинства «ординарных» приложений, все-таки определенно не хватает гибкости, покрывающей все потребности. Поэтому в расширениях POSIX реального времени вводится третий специфичный механизм создания и манипулирования с данными в потоке — собственные данные потока (thread-specific data). Использование собственных данных потока — самый простой и эффективный способ манипулирования данными, представленными индивидуальными экземплярами данных для каждого потока.
Согласно POSIX операционная система должна поддерживать ограниченное количество объектов собственных данных (POSIX.1 требует, чтобы этот предел не превышал 128 объектов на каждый процесс). Ядром системы поддерживается массив из этого количества ключей (тип pthread_key_t; это абстрактный тип, и стандарт предписывает не ассоциировать его с некоторым значением, но реально это небольшие целые значения, и в таком виде вся схема гораздо проще для понимания). Каждому ключу сопоставлен флаг, отмечающий, занят этот ключ или свободен, но это внутренние детали реализации, не доступные программисту. Кроме того, при создании ключа с ним может быть связан адрес функции деструктора, которая будет вызываться при завершении потока и уничтожении его экземпляра данных (рис. 2.4).
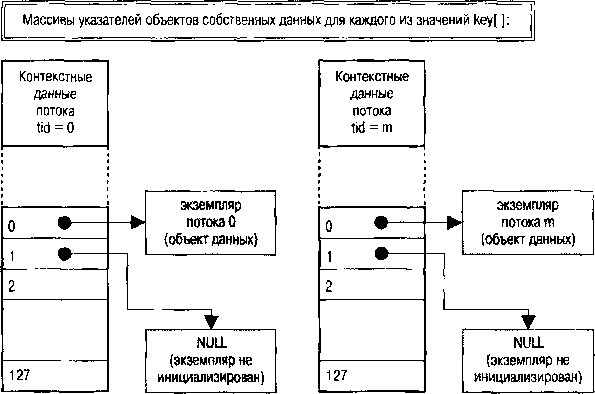
Рис. 2.4. Ключи экземпляров данных
Когда поток вызывает pthread_key_create() для создания нового типа собственных данных, система разыскивает первое незанятое значение ключа и возвращает его значение (0...127). Для каждого потока процесса (в составе описателя потока) хранится массив из 128 указателей (void*) блоков собственных данных, и по полученному ключу поток, индексируя этот массив, получает доступ к своему экземпляру данных, ассоциированных со значением ключа. Начальные значения всех указателей блоков данных - NULL, а фактическое размещение и освобождение блоков данных выполняет пользовательская программа (рис. 2.5).
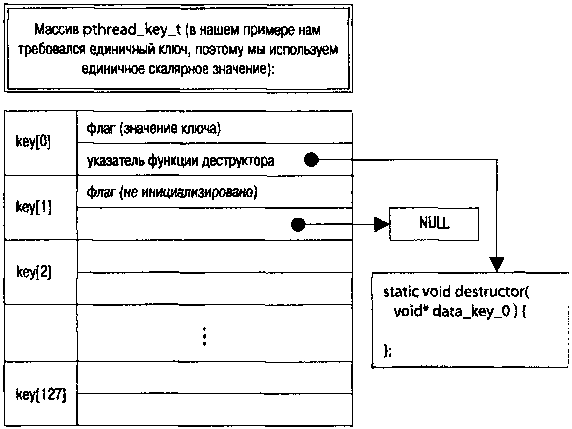
Рис. 2.5. Поток и его собственные данные
На рис. 2.5 представлен массив структур, создаваемый в единичном экземпляре для каждого процесса библиотекой потоков. Каждый элемент ключа должен быть предварительно инициализирован вызовом pthread_key_create() (однократно для всего процесса). Каждый инициализированный элемент массива определяет объекты единого класса во всех использующих их потоках, поэтому для них здесь же определяется деструктор (это в терминологии языка С!). Деструктор — единый для экземпляров данных в каждом потоке. Даже для инициализированного и используемого ключа в качестве деструктора может быть указан NULL, при этом никакие деструктивные действия при завершении потока не выполняются.
После размещения блока программа использует вызов pthread_setspecific(). Для связывания адреса своего экземпляра данных с элементом массива указателей, индексируемого ключом. В дальнейшем каждый поток использует pthread_getspecific() для доступа именно к своему экземпляру данных. Это схема, а теперь посмотрим, как она работает.
Положим, что нам требуется создать N параллельно исполняющихся идентичных потоков (использующих единую функцию потока), каждый из которых предполагает работать со своей копией экземпляра данных типа DataBlock:
class DataBlock {
~DataBlock() { ... }
...
};
void* ThreadProc(void *data) {
// ... здесь будет код, который мы рассмотрим
return NULL;
}
...
for (int i = 0; i < N; i++)
pthread_create(NULL, NULL, &ThreadProc, NULL);
Последовательность действий потока выглядит следующим образом:
1. Поток запрашивает pthread_key_create() — создание ключа для доступа к блоку данных DataBlock. Если потоку необходимо иметь несколько (m) блоков собственных данных различной типизации (и различного функционального назначения): DataBlock_1, DataBlock_2 … DataBlock_m, то он запрашивает значения ключей соответствующее число раз для каждого типа (m).
2. Неприятность здесь состоит в том, что запросить значение ключа для DataBlock должен только первый пришедший к этому месту поток (когда ключ еще не распределен). Последующие потоки, достигшие этого места, должны только воспользоваться ранее распределенным значением ключа для типа DataBlock. Для разрешения этой сложности в систему функций собственных данных введена функция pthread_once().
3. После этого каждый поток (как создавший ключ, так и использующий его) должен запросить по pthread_getspecific() адрес блока данных и, убедившись, что это NULL, динамически распределить область памяти для своего экземпляра данных, а также зафиксировать по pthread_setspecific() этот адрес в массиве экземпляров для дальнейшего использования.
4. Дальше поток может работать с собственным экземпляром данных (отдельный экземпляр на каждый поток), используя для доступа к нему pthread_getspecific().
5. При завершении любого потока система уничтожит и его экземпляр данных, вызвав для него деструктор, который был установлен вызовом pthread_key_create(), единым для всех экземпляров данных, ассоциированных с этим значением ключа.
Теперь запишем это в коде, заодно трансформировав в новую функцию ThreadProc() код ранее созданной версии этой же функции SingleProc() для исполнения в одном потоке, не являющийся реентерабельным и безопасным в многопоточной среде. (О вопросах реентерабельности мы обязательно поговорим позже.)
void* SingleProc(void *data) {
static DataBlock db( ... );
// ... операции с полями DataBlock
return NULL;
}
Примечание
To, что типы параметров и возвращаемое значение SingleProc() «подогнаны» под синтаксис ее более позднего эквивалента ThreadProc(), не является принципиальным ограничением - входную и выходную трансформации форматов данных реально осуществляют именно в многопоточном эквиваленте. Нам здесь важно принципиально рассмотреть общую формальную технику трансформации нереентерабельного кода в реентерабельный.
Далее следует код SingleProc(), преобразованный в многопоточный вид:
static pthread_key_t key;
static pthread_once_t once = PTHREAD_ONCE_INIT;
static void destructor(void* db) {
delete (DataBlock*)db;
}
static void once_creator(void) {
// создается единый на процесс ключ для данных DataBlock:
pthread_key_create(&key, destructor);
}
void* ThreadProc(void *data) {
// гарантия того, что ключ инициализируется только 1 раз на процесс!
pthread_once(&once, once_creator);
if (pthread_getspecific(key) == NULL)
pthread_setspecific(key, new DataBlock(...));
// Теперь каждый раз в теле этой функции или функций, вызываемых
// из нее, мы всегда можем получить доступ к экземпляру данных
DataBlock* pdb = pthread_getspecific(key);
// ... все те же операции с полями pdb->(DataBlock)
return NULL;
}
Примечание
Обратите внимание, что вся описанная техника преобразования потоковых функций в реентерабельные (как и все программные интерфейсы POSIX) отчетливо ориентирована на семантику классического С, в то время как все свое изложение мы ориентируем и иллюстрируем на С++. При создании экземпляра собственных данных полностью разрушается контроль типизации: разные экземпляры потоков вполне могли бы присвоить своим указателям данные (типа void*), ассоциированные с одним значением key. Это совершенно различные типы данных, скажем DataBlock_1* и DataBlock_2*. Но проявилось бы это несоответствие только при завершении функции потока и уничтожении экземпляров данных, когда к объектам совершенно разного типа был бы применен один деструктор, определенный при выделении ключа. Ошибки такого рода крайне сложны в локализации.
Особая область, в которой собственные данные потока могут найти применение и где локальные (стековые) переменные потока не могут быть использованы, — это асинхронное выполнение фрагмента кода в контексте потока, например при получении потоком сигнала.
Еще одно совсем не очевидное применение собственных данных потока (мы не встречали в литературе упоминаний о нем), которое особо органично вписывается в использование именно С++, — это еще один способ возврата в родительский поток результатов работы дочерних. При этом неважно, как были определены дочерние потоки - как присоединенные или как отсоединенные (мы обсуждали это ранее); такое использование в заметной мере нивелирует их разницу. Эта техника состоит в том, что:
• Если при создании ключа не определять деструктор экземпляра данных потока pthread_key_create(..., NULL), то при завершении потока над экземпляром его данных не будут выполняться никакие деструктивные действия и созданные потоками экземпляры данных будут существовать и после завершения потоков.
• Если к этим экземплярам данных созданы альтернативные пути доступа (а они должны быть в любом случае созданы, так как области этих данных в конечном итоге нужно освободить), то благодаря этому доступу порождающий потоки код может использовать данные, «оставшиеся» как результат выполнения потоков.
В коде (что гораздо нагляднее) это может выглядеть так (код с заметными упрощениями взят из реального завершенного проекта):
// описание экземпляра данных потока
struct throwndata {
...
};
static pthread_once_t once = PTHREAD_ONCE_INIT;
static pthread_key_t key;
void createkey(void) { pthread_key_create(&key, NULL); }
// STL-очередь, например указателей на экземпляры данных
queue<throwndata*> result;
// функция потока
void* GetBlock(void*) {
pthread_once(&once, createkey);
throwndata *td;
if ((td = (throwndata*)pthread_getspecific(key)) == NULL) {
td = new throwndata();
pthread_setspecific(key, (void*)td);
// вот он - альтернативный путь доступа:
result.push(td);
}
// далее идет плодотворная работа над блоком данных *td
// . . . . . . . . .
}
int main(int argc, char **argv) {
// . . . . . .
for (int i = 0; i < N; i++)
pthread_create(NULL, NULL, GetBlock, NULL);
// . . . . . . к этому времени потоки завершились;
// ни в коем случае нельзя помещать result.size()
// непосредственно в параметр цикла!
int n = result.size();
for (int i = 0; i < n; i++) {
throwndata *d = result.front();
// обработка очередного блока *d ...
result pop();
delete d;
}
return EXIT_SUCCESS;
}
Примечание
В предыдущих примерах кода мы указывали третий параметр pthread_create() в виде &GetBlock (адреса функции потока), но в текущем примере мы сознательно записали GetBlock. И то и другое верно, ибо компилятор достаточно умен, чтобы при указании имени функции взять ее адрес.
Собственные данные потоков — это настолько гибкий механизм, что он может таить в себе и другие, еще не используемые техники применения.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Данные потока
Данные потока В реальном коде часто возникает ситуация, когда одновременно исполняются несколько экземпляров потоков, использующих один и тот же код (при создании потоков указывается одна и та же функция потока). При этом некоторые данные (например, статические объекты,
Завершение потока
Завершение потока Как и в случае обсуждавшегося ранее завершения процесса, для потоков мы будем отчетливо различать случаи:• «естественного» завершения выполнения потока из кода самого потока;• завершения потока извне, из кода другого потока или по сигналу. Для этого
«Легковесность» потока
«Легковесность» потока Вот теперь, завершив краткий экскурс использования процессов и потоков, можно вернуться к вопросу, который вскользь уже звучал по ходу рассмотрения: почему и в каком смысле потоки часто называют «легкими процессами» (LWP — lightweight process)?Выполним ряд
Зона потока
Зона потока О сверхпроизводительном состоянии, называемом «потоком» (flow), написано много литературы. Некоторые программисты называют его «зоной». Как бы оно ни называлось, вероятно, вам знакомо это ощущение предельной концентрации сознания, в которое может войти
Создание потока
Создание потока Поток создается при первом открытии с помощью системного вызова специального файла устройства, ассоциированного с драйвером STREAMS. Как правило, процесс создает поток в два этапа: сначала создается элементарный поток, состоящий из нужного драйвера и
1.2. Сформулируйте собственные задачи
1.2. Сформулируйте собственные задачи Большинство компаний не утруждаются тщательным прописыванием целей создания и развития собственных веб-сайтов. Точнее, используют шаблонные и крайне нечеткие формулировки, которые сразу снижают потенциал проектируемой системы. Как
Собственные наборы символов и способы сортировки
Собственные наборы символов и способы сортировки Сами кодировки хранятся в файле gdsintl.dll, который находится в каталоге %INTERBASE%Intl. Вы можете самостоятельно разрабатывать и подключать свои собственные наборы символов и COLATION ORDERS в InterBase и во все его клоны. Для их разработки
12.1. Создание потока
12.1. Создание потока ПроблемаТребуется создать поток (thread) для выполнения некоторой задачи, в то время как главный поток продолжает свою работу.РешениеСоздайте объект класса thread и передайте ему функтор, который выполняет данную работу. Создание объекта потока приведет к
4.2. Отмена потока
4.2. Отмена потока Обычно поток завершается при выходе из потоковой функции или вследствие вызова функции pthread_exit(). Но существует возможность запросить из одного потока уничтожение другого. Это называется отменой, или принудительным завершением, потока.Чтобы отменить
8.4.2 Состояния Потока
8.4.2 Состояния Потока Каждый поток (istream или ostream) имеет ассоциированное с ним состояние, и обработка ошибок и нестандартных условий осуществляется с помощью соответствующей установки и проверки этого состояния.Поток может находиться в одном из следующих состояний:enum
Как разрабатывать собственные процедуры
Как разрабатывать собственные процедуры Вы рассмотрели несколько процедур, которые служат мне верой и правдой. Как вам разработать собственные? Вот некоторые моменты, на которые следует обратить внимание.• Повторяющиеся события, не включенные в расписание. Часто