Правило 40: Продумывайте подход к использованию множественного наследования
Правило 40: Продумывайте подход к использованию множественного наследования
Когда речь заходит о множественном наследовании (multiple inheritance – MI), сообщество разработчиков на C++ разделяется на два больших лагеря. Одни полагают, что раз одиночное исследование (SI) – это хорошо, то множественное наследование должно быть еще лучше. Другие говорят, что одиночное наследование – это на самом деле хорошо, а множественное не стоит хлопот. В этом правиле мы постараемся разобраться в обеих точках зрения.
Первое, что нужно уяснить для себя о множественном наследовании, – это появляющаяся возможность унаследовать одно и то же имя (функции, typedef и т. п.) от нескольких базовых классов. Это может стать причиной неоднозначности. Например:
class BorrowableItem { // нечто, что можно позаимствовать
// из библиотеки
public:
void checkOut();
...
};
class ElectronicGadget {
private:
bool checkOut() const; // выполняет самотестирование, возвращает
... // признак успешности теста
};
class MP3Player: // здесь множественное наследование (в некоторых
public BorrowableItem, // библиотеках реализована функциональность,
public ElectronicGadget // необходимая для MP3-плееров)
{...} // определение класса не важно
MP3Player mp;
mp.checkout(); // неоднозначность! какой checkOut?
Отметим, что в этом примере вызов функции checkOut неоднозначен, несмотря на то что доступна лишь одна из двух функций. (checkOut открыта в классе Borrowableltem и закрыта в классе ElectronicGadget.) И это согласуется с правилами разрешения имен перегруженных функций в C++: прежде чем проверять права доступа, C++ находит функцию, которая наиболее соответствует вызову. И только потом проверяется, доступна ли наиболее подходящая функция. В данном случае оба варианта функции checkOut одинаково хорошо соответствуют вызову, то есть ни одна из них не подходит лучше, чем другая. А стало быть, до проверки доступности ElectronicGadget::checkOut дело не доходит.
Чтобы разрешить неоднозначность, вы можете указать имя базового класса, чью функцию нужно вызвать:
mp.BorrowableItem::checkOut(); // вот какая checkOut мне нужна!
Вы, конечно, также можете попытаться явно вызвать ElectronicGadget::check-Out, но тогда вместо ошибки неоднозначности получите другую: «вы пытаетесь вызвать закрытую функцию-член».
Множественное наследование просто означает наследование более, чем от одного базового класса, но вполне может возникать также и в иерархиях, содержащих более двух уровней. Это может привести к «ромбовидному наследованию»:
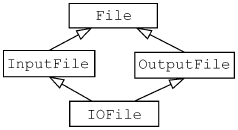
class File {...};
class InputFile: public File {...};
class OutputFile: public File {...};
class IOFile: public InputFile,
public OutputFile
{...};
Всякий раз, когда вы строите иерархию наследования, в которой от базового класса к производному ведет более одного пути (как в приведенном примере: от File к IOFile можно пройти как через InputFile, так и через OutputFile), вам приходится сталкиваться с вопросом о том, должны ли данные-члены базового класса дублироваться в объекте подкласса столько раз, сколько имеется путей. Например, предположим, что в классе File есть член filename. Сколько копий этого поля должно быть в классе IOFile? С одной стороны, он наследует по одной копии от каждого из своих базовых классов, следовательно, всего будет два члена данных с именем fileName. С другой стороны, простая логика подсказывает, что объект IOFile имеет только одно имя файла, поэтому поле fileName, наследуемое от двух базовых классов, не должно дублироваться.
C++ не принимает ничью сторону в этом споре. Он успешно поддерживает оба варианта, хотя по умолчанию предполагается дублирование. Если это не то, что вам нужно, сделайте класс, содержащий данные (то есть File), виртуальным базовым классом. Для этого все непосредственные потомки должны использовать виртуальное наследование:
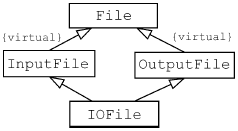
class File {...};
class InputFile: virtual public File {...};
class OutputFile: virtual public File {...};
class IOFile: public InputFile,
public OutputFile
{...};
В стандартной библиотеке C++ есть похожая иерархия, только классы в ней являются шаблонными и называются basic_ios, basic_istream, basic_ostream и basic_iostream, в не File, InputFile, OutputFile и IOFile.
С точки зрения корректности, открытое наследование всегда должно быть виртуальным. Если бы это была единственная точка зрения, то правило было бы простым: всякий раз при открытом наследовании используйте виртуальное открытое наследование. К сожалению, корректность – не единственное, что нужно принимать во внимание. Чтобы избежать дублирования унаследованных членов, компилятору приходится прибегать к нетривиальным трюкам, из-за чего размер объектов классов, использующих множественное виртуальное наследование, обычно оказывается больше по сравнению со случаем, когда виртуальное наследование не используется. Доступ к данным-членам виртуальных базовых классов также медленнее, чем к данным невиртуальных базовых классов. Детали реализации зависят от компилятора, но суть остается неизменной: виртуальное наследование требует затрат.
Оно обходится не бесплатно еще и по другой причине. Правила, определяющие инициализацию виртуальных базовых классов, сложнее и интуитивно не так понятны, как правила для невиртуальных базовых классов. Ответственность за инициализацию виртуального базового класса ложится на самый дальний производный класс в иерархии. Отсюда следует, что: (1) классы, наследующие виртуальному базовому и требующие инициализации, должны знать обо всех своих виртуальных базовых классах, независимо от того, как далеко они от них находятся в иерархии, и (2) когда в иерархию добавляется новый производный класс, он должен принять на себя ответственность за инициализацию виртуальных предков (как прямых, так и непрямых).
Мой совет относительно виртуальных базовых классов (то есть виртуального наследования) прост. Во-первых, не применяйте виртуальных базовых классов до тех пор, пока в этом не возникнет настоятельная потребность. По умолчанию используйте невиртуальное наследование. Во-вторых, если все же избежать виртуальных базовых классов не удается, старайтесь не размещать в них данных. Тогда можно будет забыть о странностях правил инициализации (да, кстати, и присваивания) таких классов. Неспроста интерфейсы Java и. NET, которые во многом подобны виртуальным базовым классам C++, не могут содержать никаких данных.
Теперь рассмотрим следующий интерфейсный класс C++ (см. правило 31) для моделирования физических лиц:
class IPerson {
public:
virtual ~IPerson();
virtual std::string name() const = 0;
virtual std::string birthDate() const = 0;
};
Пользователи IPerson должны программировать в терминах указателей и ссылок на IPerson, поскольку создавать объекты абстрактных классов запрещено. Для создания объектов, которыми можно манипулировать как объектами IPerson, используются функции-фабрики (опять же см. правило 31), которые порождают объекты конкретных классов, производных от IPerson:
// функция-фабрика для создания объекта Person по уникальному
// идентификатору из базы данных; см. в правиле 18,
// почему возвращаемый тип – не обычный указатель
std::tr1::shared_ptr<IPerson> makePerson(DatabaseID personIdentifier);
// функция для запроса идентификатора у пользователя
DatabaseID askUserForDtabaseID();
DatabaseID id(askUserForDtabaseID());
std::tr1::shared_ptr<IPerson> pp(makePerson(id)); // создать объект,
// поддерживающий
// интерфейс IPerson
... // манипулировать *pp
// через функции-члены
// IPerson
Но как makePerson создает объекты, на которые возвращает указатель? Ясно, что должен быть какой-то конкретный класс, унаследованный от IPerson, который makePerson может инстанцировать.
Предположим, этот класс называется CPerson. Будучи конкретным классом, CPerson должен предоставлять реализацию чисто виртуальных функций, унаследованных от IPerson. Можно написать его «с нуля», но лучше воспользоваться уже готовыми компонентами, которые делают большую часть работы. Например, предположим, что старый, ориентированный только на базы данных класс Person-Info предоставляет почти все необходимое CPerson:
class PersonInfo {
public:
explicit PersonInfo(DatabaseID pid)
virtual ~PersonInfo();
virtual const char *theName() const;
virtual const char *theBirthDate() const;
...
private:
virtual const char *valeDelimOpen() const; // ??. ????
virtual const char *valeDelimClose() const;
...
};
Понять, что этот класс старый, можно хотя бы потому, что функции-члены возвращают const char* вместо объектов string. Но если ботинки подходят, почему бы не носить их? Имена функций-членов класса наводят на мысль, что результат может оказаться вполне удовлетворительным.
Вскоре вы приходите к выводу, что класс PersonInfo был спроектирован для печати полей базы данных в различных форматах, с выделением начала и конца каждого поля специальными строками-разделителями. По умолчанию открывающим и закрывающим разделителями служат квадратные скобки, поэтому значение поля «Ring-tailed Lemur» будет отформатировано так:
[Ring-tailed Lemur]
Учитывая тот факт, что квадратные скобки не всегда приемлемы для пользователей PersonInfo, в классе предусмотрены виртуальные функции valeDelimOpen и valeDelimClose, позволяющие производным классам задать другие открывающие и закрывающие строки-разделители. Функции-члены PersonInfo вызывают эти виртуальные функции для добавления разделителей к возвращаемым значениям. Так, функция PersonInfo::theName могла бы выглядеть следующим образом:
const char *PersonInfo::valueDelimOpen() const
{
return “[“; // открывающий разделитель по умолчанию
}
const char *PersonInfo::valueDelimClose() const
{
return “]“; // закрывающий разделитель по умолчанию
}
const char * PersonInfo::theName() const
{
// резервирование буфера для возвращаемого значения; поскольку он
// статический, автоматически инициализируется нулями
static char value[Max_Formatted_Field_Value_Length];
// скопировать открывающий разделитель
std::strcpy(value, valueDelimOpen());
добавить к строке value значение из поля name объекта (будьте осторожны –
избегайте переполнения буфера!)
// скопировать закрывающий разделитель
std::strcpy(value, valueDelimClose());
return value;
}
Кто-то может посетовать на устаревший подход к реализации PersonInfo::theName (особенно это касается использования статического буфера фиксированного размера, опасного возможностью переполнения и потенциальными проблемами в многопоточной среде – см. правило 21), но оставим этот вопрос в стороне и сосредоточимся вот на чем: функция theName вызывает valueDelimOpen для получения открывающего разделителя, вставляемого в возвращаемую строку, затем дописывает имя и в конце вызывает valueDelimClose.
Поскольку valueDelimOpen и valueDelimClose – виртуальные функции, возвращаемый результат theName зависит не только от PersonInfo, но и от классов, производных от него.
Для разработчика CPerson это хорошая новость, потому что, внимательно просматривая документацию по функциям печати из класса IPerson, вы обнаруживаете, что функции name и birthDate должны возвращать неформатированные значения, то есть без добавления разделителей. Другими словами, если человека зовут Homer, то вызов функции name должен возвращать «Homer», а не «[Homer]».
Взаимосвязь между CPerson и PersonInfo можно описать так: PersonInfo упрощает реализацию некоторых функций CPerson. И это все! Стало быть, речь идет об отношении «реализован посредством», и, как мы знаем, такое отношение можно представить двумя способами: с помощью композиции (см. правило 38) или закрытого наследования (см. правило 39). В правиле 39 отмечено, что композиция в общем случае более предпочтительна, но если нужно переопределять виртуальные функции, то требуется наследование. В данном случае CPerson должен переопределить valueDelimOpen и valueDelimClose – задача, которая с помощью композиции не решается. Самое очевидное решение – применить закрытое наследование CPerson от PersonInfo, хотя, как объясняется в правиле 39, это потребует несколько больше работы. Можно также при реализации CPerson воспользоваться сочетанием композиции и наследования с целью переопределения виртуальных функций PersonInfo. Но мы остановимся просто на закрытом наследовании.
Однако CPerson также должен реализовать интерфейс IPerson, а для этого требуется открытое наследование. Вот мы и пришли к множественному наследованию: сочетанию открытого наследования интерфейса с закрытым наследованием реализации:
class IPerson { // класс описывает интерфейс,
public: // который должен быть реализован
virtual ~IPerson();
virtual std::string name() const = 0;
virtual std::string birthDate() const = 0;
};
class DatabaseID {...}; // используется далее;
// детали не существенны
class PersonInfo { // в этом классе имеет функции,
public: // помогающие при реализации
explicit PersonInfo(DatabaseID pid) // интерфейса IPerson
virtual ~PersonInfo();
virtual const char *theName() const;
virtual const char *theBirthDate() const;
virtual const char *valeDelimOpen() const;
virtual const char *valeDelimClose() const;
...
};
class CPerson: public IPerson, private PersonInfo { // используется
public: // множественное
explicit CPerson(DatabaseID pid): PersonInfo(pid) {} // наследование
virtual std::string name() const // реализации
{ return PersonInfo::theName();} // функций-членов
// из интерфейса
// IPerson
virtual std::string birthDate() const
{ return PersonInfo::theBirthDate();}
private: // переопределения
const char * valeDelimOpen() const { return “”;} // унаследованных
const char * valeDelimClose() const { return “”;} // виртуальных
}; // функций,
// возвращающих
// строки-разделители
В нотации UML это решение выглядит так:
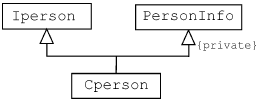
Рассмотренный пример показывает, что множественное наследование может быть и удобным, и понятным.
Замечу, что множественное наследование – просто еще один инструмент в объектно-ориентированном инструментарии. По сравнению с одиночным наследованием оно несколько труднее для понимания и применения, поэтому если вы можете спроектировать программу с одним лишь одиночным наследованием, который более или менее эквивалентен варианту с множественным наследованием, то, скорее всего, предпочтение следует отдать первому подходу. Если вам кажется, что единственно возможный вариант дизайна требует применения множественного наследования, то рекомендую как следует подумать – почти наверняка найдется способ обойтись одиночным. В то же время иногда множественное наследование – это самый ясный, простой для сопровождения и разумный способ достижения цели. В таких случаях не бойтесь применять его. Просто делайте это, тщательно обдумав все последствия.
Что следует помнить
• Множественное наследование сложнее одиночного. Оно может привести к неоднозначности и необходимости применять виртуальное наследование.
• Цена виртуального наследования – дополнительные затраты памяти, снижение быстродействия и усложнение операций инициализации и присваивания. На практике его разумно применять, когда виртуальные базовые классы не содержат данных.
• Множественное наследование вполне законно. Один из сценариев включает комбинацию открытого наследования интерфейсного класса и закрытого наследования класса, помогающего в реализации.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Синтаксис множественного фона
Синтаксис множественного фона Поставить эти четыре изображения в качестве фона элемента body очень просто с использованием нового синтаксиса CSS3:body { background: url(../img/stars-1.png) repeat-x fixed -130% 0, url(../img/stars-2.png) repeat-x fixed 40% 0, url(../img/space-bg.png) repeat-x fixed -80% 0, url(../img/clouds.png) repeat-x fixed 100% 0; background-color: #1a1a1a;
Проблема наследования
Проблема наследования Если существует необходимость наследовать от класса Singleton, то следует придерживаться определенных правил.Во-первых, класс-наследник должен переопределить метод Instance(), так, чтобы создавать экземпляр производного класса. Если не предполагается, что
Глава 8. Изучение наследования
Глава 8. Изучение наследования НаследованиеНаследованием (inheritance) называется такое отношение между классами, когда один класс использует часть структуры и/или поведения другого или нескольких классов. При наследовании создается иерархия абстракций, в которой подкласс
Правило 2: Предпочитайте const, enum и inline использованию #define
Правило 2: Предпочитайте const, enum и inline использованию #define Это правило лучше было бы назвать «Компилятор предпочтительнее препроцессора», поскольку #define зачастую вообще не относят к языку C++. В этом и заключается проблема. Рассмотрим простой пример; попробуйте написать
Правило 14: Тщательно продумывайте поведение при копировании классов, управляющих ресурсами
Правило 14: Тщательно продумывайте поведение при копировании классов, управляющих ресурсами В правиле 13 изложена идея Получение Ресурса Есть Инициализация (Resource Acquisition Is Initialization – RAII), лежащая в основе создания управляющих ресурсами классов. Было также показано, как эта
Правило 39: Продумывайте подход к использованию закрытого наследования
Правило 39: Продумывайте подход к использованию закрытого наследования В правиле 32 показано, что C++ рассматривает открытое наследование как отношение типа «является». В частности, говорится, что компиляторы, столкнувшись с иерархией, где класс Student открыто наследует
18.6. Пример множественного виртуального наследования A
18.6. Пример множественного виртуального наследования A Мы продемонстрируем определение и использование множественного виртуального наследования, реализовав иерархию шаблонов классов Array (см. раздел 2.4) на основе шаблона Array (см. главу 16), модифицированного так, чтобы он
19. Применение наследования в C++
19. Применение наследования в C++ При использовании наследования указатель или ссылка на тип базового класса способен адресовать объект любого производного от него класса. Возможность манипулировать такими указателями или ссылками независимо от фактического типа
2.2.4. Типы сущностей и иерархия наследования
2.2.4. Типы сущностей и иерархия наследования Как было указано выше, связи определяют, является ли сущность независимой или зависимой. Различают несколько типов зависимых сущностей.Характеристическая - зависимая дочерняя сущность, которая связана только с одной
Просмотр дерева наследования классов
Просмотр дерева наследования классов ClassView предоставляет очень интересную и полезную возможность просмотра дерева наследования классов приложения. Для этого выберите название интересующего вас класса из списка классов и откройте временное меню, нажав правую кнопку
Смысл наследования
Смысл наследования Мы уже рассмотрели основные способы наследования. Многое еще предстоит изучить, в частности, множественное наследование и детали того, что происходит с утверждениями в контексте наследования (понятие субконтрактов).Но вначале следует поразмышлять
Примеры множественного наследования
Примеры множественного наследования Множественное наследование это, по сути, прямое приложение уже рассмотренных принципов наследования, - класс вправе иметь произвольное число родителей. Однако, изучая этот вопрос более внимательно, можно обнаружить две интересные
Лекция 16. Техника наследования
Лекция 16. Техника наследования Наследование - ключевая составляющая ОО-подхода к повторному использованию и расширяемости. В этой лекции нам предстоит исследовать новые возможности, разнородные, но демонстрирующие замечательные следствия красоты базисных идей.
Глобальная структура наследования
Глобальная структура наследования Ранее мы уже ссылались на универсальные (universal) классы GENERAL и ANY, а также на безобъектный (objectless) класс NONE. Пришло время пояснить их роль и представить глобальную структуру
Подход №1: «Не начинать новые истории, пока старые не будут готовы к реальному использованию»
Подход №1: «Не начинать новые истории, пока старые не будут готовы к реальному использованию» Звучит классно, не так ли? Вас тоже греет эта мысль? :)Несколько раз мы уже было решались на этот подход, и даже рисовали теоретические модели того, как бы могли это сделать. Но