18.5.3. Инструментальная связка DocBook
18.5.3. Инструментальная связка DocBook
Обычно для создания XHTML-документа из исходного DocBook-текета используется интерфейсный сценарий xmko(1). Ниже приводятся примерные команды.
bash$ xmlto xhtml foo.xml bash$ Is *.html
ar01s02.html ar0ls03.html ar01s04.html index.html
В данном примере XML-DocBook-документ с именем f оо. xml, содержащий три раздела верхнего уровня, преобразовывается в индексную страницу и три части. Также просто создать одну большую страницу.
bash$ xmlto xhtml-nochunks foo.xml
bash$ Is *.html
foo.html
Наконец, ниже приводятся команды для создания PostScript-представления для печати.
bash$ xmlto ps foo.xml # Создание PostScript
bash$ Is *.ps
foo.ps
Для того чтобы превратить существующие документы в HTML или PostScript, необходимо ядро, которое способно применить к данным документам комбинацию DocBook DTD и подходящей таблицы стилей. На рис. 18.2 показано, как для данной цели совместно используются инструменты с открытым исходным кодом.
Синтаксический анализ документа и его трансформация на основе таблицы стилей будет осуществляться одной из трех программ. Вероятнее всего, программой xsltproc, которая представляет собой синтаксический анализатор, поставляемый с Red Hat Linux. Два другие варианта представлены Java-программами Saxon и Xalan.
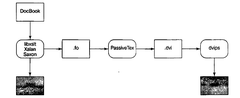
Рис. 18.2. Современная инструментальная связка XML-DocBook
Сгенерировать высококачественный XHTML-документ из любого DocBook-текста сравнительно просто. Большую роль в данном случае играет тот факт, что XHTML является просто другим XML DTD-определением. Преобразование в HTML-документ осуществляется путем применения довольно простой таблицы стилей. Данный способ позволяет также просто генерировать RTF-документы, а из XHTML или RTF легко создать простой ASCII-текст.
Сложный случай представляет собой печать. Создание высококачественного распечатываемого вывода, что на практике означает преобразование в формат Adobe PDF (Portable Document Format), затруднено. Правильное решение данной задачи требует алгоритмического воспроизведения способа мышления наборщика (человека) при переходе от содержания к уровню представления.
Таким образом, прежде всего, с помощью таблицы стилей структурированная разметка DocBook преобразовывается в другой диалект XML— FO (Formatting Objects — объекты форматирования). FO-разметка является ярко выраженной разметкой уровня представления. Ее можно представить как некоторый функциональный XML-эквивалент troff. Данную разметку необходимо преобразовывать в PostScript для упаковки в PDF.
В инструментальной связке, поставляемой с Red Hat Linux, данная задача решается с помощью TjX-макропакета, который называется PassiveTeX. Данный макрос преобразовывает объекты форматирования, генерируемые xsltproc, в язык TgX Дональда Кнутта. Затем вывод Т|Х, называемый форматом DVI (DeVice Independent), преобразовывается в PDF.
Сложная цепь XML, TgX-макрос, DVI, PDF — неуклюжая конструкция. Она "гремит, хрипит и имеет уродливые наросты". Шрифты являются значительной проблемой, поскольку XML, TjX и PDF имеют очень разные модели. Кроме того, серьезные трудности связаны с поддержкой интернационализации и локализации. Единственной привлекательной особенностью данной конструкции является то, что она работает.
Изящным способом разрешения описываемой проблемы будет использование FOP, непосредственного преобразования FO в PostScript, разрабатываемого проектом Apache. С помощью FOP проблема интернационализации даже если и не будет решена полностью, то, по крайней мере, будет определена. XML-инструменты поддерживают Unicode на всем пути к FOP. Преобразование глифов Unicode в Post-Script-шрифт является также исключительно проблемой FOP. Единственным недостатком данного подхода является то, что он пока не работает. В середине 2003 года FOP находился в незаконченной альфа-стадии. FOP-преобразование можно использовать, однако оно содержит множество "необработанных углов" и характеризуется недостатком функций.
На рис. 18.3 иллюстрируется схема инструментальной связки FOP.
У FOP есть конкурент. Другой проект, который называется xsl-fo-proc, предназначен для решения тех же задач, что и FOP, но написан на С++ (и, следовательно, работает быстрее, чем Java, и не зависит от Java-окружения). В середине 2003 года проект xsl-fo-proc находился в незавершенной альфа-стадии и продвинулся не дальше, чем FOP.
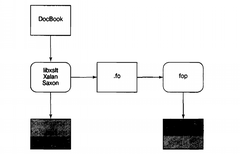
Рис. 18.3. Будущая инструментальная связка XML-DocBook с использованием FOP
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Инструментальная панель
Инструментальная панель Инструментальная панель включена в редакторе Geany по умолчанию, хотя, как мы видели, расширения рабочего пространства ради, её можно и убрать — временно, через меню Вид, или постоянно, через пункты Правка -> Параметры. Действия через пиктограммы в
16.3. Связка Apache + PHP + MySQL
16.3. Связка Apache + PHP + MySQL Настроить данную связку, которая очень полезна при Web-программировании, можно двумя способами. Первый из них — это использовать программы, которые входят в состав дистрибутива и, как правило, устанавливаются из пакетов RPM. Второй способ заключается
Инструментальная палитра
Инструментальная палитра Чтобы вызвать инструментальную палитру, выполните команду ленты View ? Palettes ? Tool Palettes (Вид ? Палитры ? Инструментальные палитры). На инструментальной палитре содержатся кнопки вызова инструментов, сгруппированные по их функциональному назначению
18.3.6. DocBook
18.3.6. DocBook DocBook представляет собой определение типов SGML- и XML-документов, предназначенное для крупных, сложных технических документов. Данный формат является единственным исключительно структурированным среди форматов разметки, используемых в Unix-сообществе. Инструмент
18.5. DocBook
18.5. DocBook Большое количество главных проектов с открытым исходным кодом сходятся в том, что DocBook является стандартным форматом их документации. Сторонники разметки, основанной на XML, видимо, выиграли теоретический спор против разметки уровня представления и в пользу
18.5.3. Инструментальная связка DocBook
18.5.3. Инструментальная связка DocBook Обычно для создания XHTML-документа из исходного DocBook-текета используется интерфейсный сценарий xmko(1). Ниже приводятся примерные команды.bash$ xmlto xhtml foo.xml bash$ Is *.htmlar01s02.html ar0ls03.html ar01s04.html index.htmlВ данном примере XML-DocBook-документ с именем f оо. xml,
18.5.8. Справочные ресурсы по XML-DocBook
18.5.8. Справочные ресурсы по XML-DocBook Одним из факторов, который затрудняет изучение DocBook, является то, что сайты, связанные с данной темой, часто перегружают новичков длинными списками W3C-стандартов, массивными упражнениями по SGML-идеологии и абстрактной терминологией.
18.3.6. DocBook
18.3.6. DocBook DocBook представляет собой определение типов SGML- и XML-документов, предназначенное для крупных, сложных технических документов. Данный формат является единственным исключительно структурированным среди форматов разметки, используемых в Unix-сообществе. Инструмент
18.5. DocBook
18.5. DocBook Большое количество главных проектов с открытым исходным кодом сходятся в том, что DocBook является стандартным форматом их документации. Сторонники разметки, основанной на XML, видимо, выиграли теоретический спор против разметки уровня представления и в пользу
18.5.8. Справочные ресурсы по XML-DocBook
18.5.8. Справочные ресурсы по XML-DocBook Одним из факторов, который затрудняет изучение DocBook, является то, что сайты, связанные с данной темой, часто перегружают новичков длинными списками W3C-стандартов, массивными упражнениями по SGML-идеологии и абстрактной терминологией.
1.1. Инструментальная среда BPwin 4.0
1.1. Инструментальная среда BPwin 4.0 1.1.1. Общее описание интерфейса BPwin 4.0 BPwin имеет достаточно простой и интуитивно понятный интерфейс пользователя, дающий возможность аналитику создавать сложные модели при минимальных усилиях. Рис. 1.1.1. Интегрированная среда разработки
2.2.2. Инструментальная среда RPTwin
2.2.2. Инструментальная среда RPTwin После выбора типа отчета в диалоге New Report и задания необходимых опций отчет создается автоматически. В окне RPTwin показывается окно DataSet Columns и шаблон отчета (рис. 2.2.3). Рис. 2.2.3. Шаблон отчетаШаблон отчета включает несколько секций:Report Header -
Инструментальная палитра
Инструментальная палитра Чтобы вызвать инструментальную палитру, выполните команду ленты View ? Palettes ? Tool Palettes (Отображение ? Палитры ? Инструментальные палитры). На инструментальной палитре содержатся кнопки вызова инструментов, сгруппированные по их функциональному
1.1. Инструментальная среда BPwin
1.1. Инструментальная среда BPwin BPwin имеет достаточно простой и интуитивно понятный интерфейс пользователя, дающий возможность аналитику создавать сложные модели при минимальных усилиях. Ниже будет описан интерфейс версии 2.5. Рис. 1.1. Интегрированная среда разработки
5.1.2. Инструментальная среда RPTwin
5.1.2. Инструментальная среда RPTwin После выбора типа отчета в диалоге New Report и задания необходимых опций отчет создается автоматически. Ниже будет описан интерфейс версии 3.02.В окне RPTwin показывается окно DataSet Columns и шаблон отчета (рис. 5.3). Рис. 5.3. Шаблон отчета Шаблон отчета