Тестирование на скоростях и в масштабах Google Пуджа Гупта, Марк Айви и Джон Пеникс
Тестирование на скоростях и в масштабах Google
Пуджа Гупта, Марк Айви и Джон Пеникс
Системы непрерывной интеграции — главные герои обеспечения работоспособности программного продукта во время разработки. Типичная схема работы большинства систем непрерывной интеграции такая.
1. Получить последнюю копию кода.
2. Выполнить все тесты.
3. Сообщить о результатах.
4. Перейти к пункту 1.
Решение отлично справляется с небольшой кодовой базой, пока динамичность изменений кода не выходит за рамки, а тесты прогоняются быстро. Чем больше становится кода, тем сильнее падает эффективность подобных систем. Добавление нового кода увеличивает время «чистого» запуска, и в один прогон включается все больше изменений. Если что-то сломается, найти и исправить изменение становится все сложнее.
Разработка программных продуктов в Google происходит быстро и с размахом. Мы добавляем в базу кода всего Google больше 20 изменений в минуту, и 50% файлов в ней меняются каждый месяц. Разработка и выпуск всех продуктов опираются на автотесты, проверяющие поведение продукта. Есть продукты, которые выпускаются несколько раз в день, другие — раз в несколько недель.
По идее, при такой огромной и динамичной базе кода команды должны тратить кучу времени только на поддержание сборки в состоянии «зеленого света». Система непрерывной интеграции должна помогать с этим. Она должна сразу выделять изменение, приводящее к сбою теста, а не просто указывать на набор подозрительных изменений или, что еще хуже, перебирать их все в поисках нарушителя.
Чтобы решить эту проблему, мы построили систему непрерывной сборки (рис. 2.6), которая анализирует зависимости и выделяет только те тесты, которые связаны с конкретным изменением, а потом выполняет только их. И так для каждого изменения. Система построена на инфраструктуре облачных вычислений Google, которая позволяет одновременно выполнять большое количество сборок и запускать затронутые тесты сразу же после отправки изменений.
Примером ниже мы показываем, как наша система дает более быструю и точную обратную связь, чем типичная непрерывная сборка. В нашем сценарии используются два теста и три изменения, затрагивающие эти тесты. Тест gmail_server_tests падает из-за изменения 2. Типичная система непрерывной сборки сообщила бы, что к сбой случился из-за изменения 2 или 3, не уточняя. Мы же используем механизм параллельного выполнения, поэтому запускаем тесты независимо, не дожидаясь завершения текущего цикла «сборка–тестирование». Анализ зависимостей сузит набор тестов для каждого изменения, поэтому в нашем примере общее количество выполнений теста то же самое.
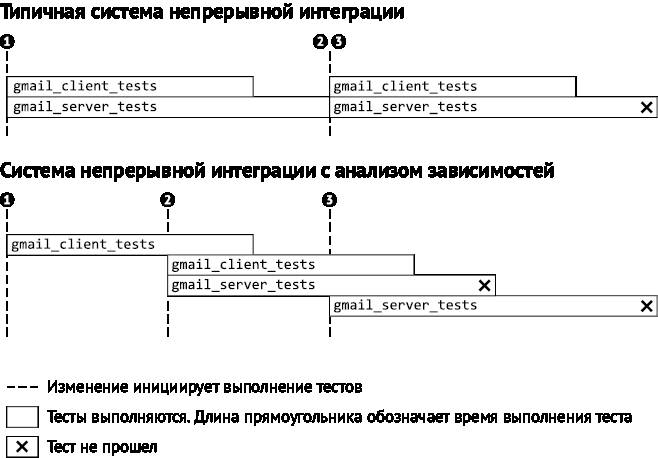
Рис. 2.6. Сравнение систем непрерывной интеграции
Наша система берет данные о зависимостях из спецификаций сборки, которые описывают, как компилируется код и какие файлы входят в сборку приложения и теста. Правила сборки имеют четкие входные и выходные данные, объединив которые получим точное описание процесса сборки. Наша система строит в памяти график зависимостей сборки, как на рис. 2.7, и обновляет его с каждым новым изменением. На основании этой схемы мы определяем все тесты, связанные прямо или косвенно с кодом, вошедшим в изменение. Именно эти тесты нужно запустить, чтобы узнать текущее состояние сборки. Давайте посмотрим на пример.
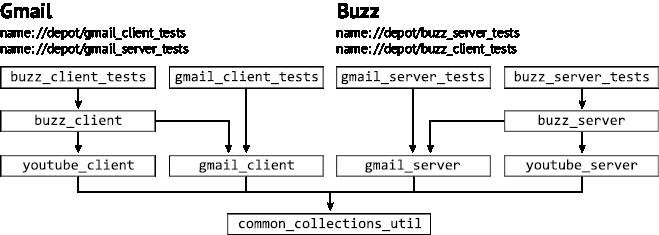
Рис. 2.7. Пример зависимостей сборки
Мы видим, как два отдельных изменения в коде, находящихся на разных уровнях дерева зависимостей, анализируются, чтобы подобрать минимальный набор тестов, который определит, дать ли зеленый свет проектам Gmail и Buzz.
Сценарий 1: изменение в общей библиотеке
Для первого сценария возьмем изменение, которое модифицирует файлы в common_collections_util, как показано на рис. 2.8.
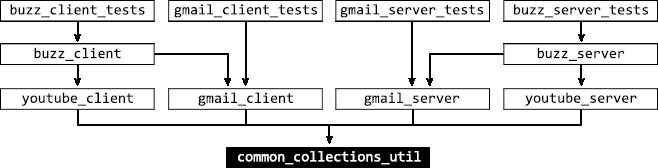
Рис. 2.8. Изменение в common_collections_util.h
Отправив изменение, мы перемещаемся по линиям зависимостей вверх по графику. Так мы найдем все тесты, зависящие от изменений. Когда поиск завершится, а это займет лишь доли секунды, у нас будут все тесты, которые нужно прогнать, и мы получим актуальные статусы наших проектов (рис. 2.9).
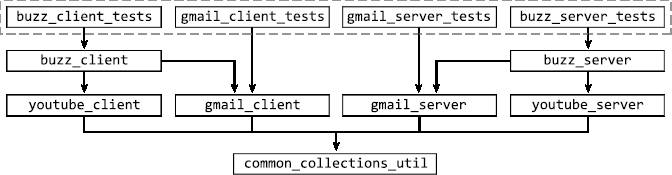
Рис. 2.9. Тесты, на которые влияет изменение
Сценарий 2: изменение в зависимом проекте
Во втором примере возьмем изменение, которое модифицирует файлы в youtube_client (рис. 2.10).
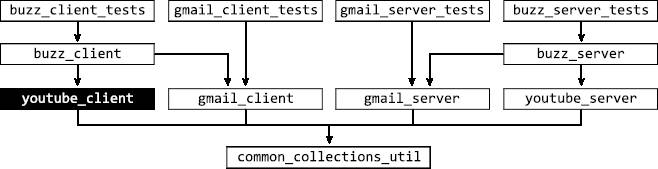
Рис. 2.10. Изменение в youtube_client
Проведя аналогичный анализ, мы определим, что изменение влияет только на buzz_client_tests и что нужно актуализировать статус проекта Buzz (рис. 2.11).
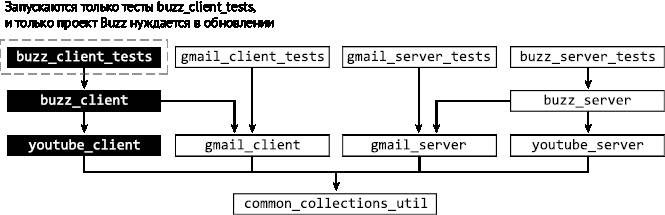
Рис. 2.11. Buzz нужно обновить
Примеры показывают, как мы оптимизируем количество тестов, прогоняемых для одного изменения, без потери в точности результатов. Уменьшение количества тестов для одного изменения позволяет выполнить все нужные тесты для каждого зафиксированного изменения. Нам становится легче выявлять и отлаживать проблемы в проблемном изменении.
Умные инструменты и возможности инфраструктуры облачных вычислений сделали систему непрерывной интеграции быстрой и надежной. И мы постоянно стараемся ее улучшить, хотя она уже используется в тысячах проектов Google, чтобы выпускать проекты быстрее и проводить больше итераций. И — что важно — наш прогресс замечают пользователи.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 5. Как мы улучшали тестирование в Google
Глава 5. Как мы улучшали тестирование в Google Все тестирование в Google можно описать одной фразой: забота о качестве — это ежедневная обязанность каждого инженера. Если это делается на совесть — уровень качества растет. Новый код становится чище, ранние сборки — устойчивее.
Нагрузочное тестирование, продолжительное тестирование и тестирование стабильности
Нагрузочное тестирование, продолжительное тестирование и тестирование стабильности Команда тестирования создает и выполняет продолжительные тесты на физическом оборудовании в лаборатории. Не забыть про внедрение неисправностей (fault
Google I/O: новый Android, Google TV и машинное обучение Андрей Письменный
Google I/O: новый Android, Google TV и машинное обучение Андрей Письменный Опубликовано 21 мая 2010 года Несмотря на то, что первый день конференции I/O, проводимой компанией Google для разработчиков, принёс много интересных анонсов, во второй, заключительный её день,
Марк Шаттлуорт — Стив Джобс от Linux Михаил Карпов
Марк Шаттлуорт — Стив Джобс от Linux Михаил Карпов Опубликовано 11 мая 2010 года Почему именно Ubuntu стал самым популярным дистрибутивом Linux? Почему именно он приобрёл такую известность, что для многих Linux и Ubuntu превратились почти что в синонимы? Ответ на
Распад битов[225] Марк Дери[226]
Распад битов[225] Марк Дери[226] В медиатусовке мало кто расстроился, узнав о его уходе, но вот лично автор этой статьи сожалеет о том, что мы уже не сможем придираться к Хитрому Нику. В декабре 1998 года Николас Негропонте из Wired, директор Лаборатории медиа Массачусетского
Конференция D8: Стив Джобс, Марк Цукерберг и Джеймс Кэмерон Павел Борисов
Конференция D8: Стив Джобс, Марк Цукерберг и Джеймс Кэмерон? Павел Борисов Опубликовано 03 июня 2010 года Раз в год журналисты The Wall Street Journal Уолтер Моссберг и Кара Свишер зовут главных людей ИТ-индустрии и безо всякого заготовленного сценария
Google устанавливает торговые автоматы для продажи приложений из Google Play Николай Маслухин
Google устанавливает торговые автоматы для продажи приложений из Google Play Николай Маслухин Опубликовано 04 октября 2013 Популярность торговых автоматов в Японии широко известна, и купить в них можно многое — от жевательной резинки до бытовой
Почему Google не показала новый Android и другие разочарования Google I/O 2013 Николай Маслухин
Почему Google не показала новый Android и другие разочарования Google I/O 2013 Николай Маслухин Опубликовано 21 мая 2013 В прошлом году на конференции Google I/O 2012 было жарко. Среди новинок, о которых говорили со сцены, были Nexus7, Project Glass, Android 4.1, Google Now и
ОКНО ДИАЛОГА: Марк Шаттлворт: «Со временем весь софт будет свободным»
ОКНО ДИАЛОГА: Марк Шаттлворт: «Со временем весь софт будет свободным» Автор: Дмитрий ЛяховМарк Шаттлворт (Mark Shuttleworth) — фигура в мире высоких технологий необычная. Будучи отцом Ubuntu Linux, Марк известен прежде всего как второй космический турист, побывавший в космосе вслед за
Тестирование приложений для Android как инструмент выхода в ТОП на Google Play Дмитрий Куриленко, компания Promwad
Тестирование приложений для Android как инструмент выхода в ТОП на Google Play Дмитрий Куриленко, компания Promwad Опубликовано 13 марта 2013По итогам 2012 года операционная система Android стала лидером среди мобильных платформ: её доля на мировом рынке превысила 53 процента. Для
Без Google Reader: чем заменить незаменимый сервис Google, что теперь делать и кто в этом виноват Олег Парамонов
Без Google Reader: чем заменить незаменимый сервис Google, что теперь делать и кто в этом виноват Олег Парамонов Опубликовано 15 марта 2013 Компания Google объявила, что планирует закрыть RSS-агрегатор Google Reader. Это катастрофа, и не только для тех, кто пользовался
Марк Андриссен пророчит смерть традиционному ритейлу. Не рановато ли? Денис Викторов
Марк Андриссен пророчит смерть традиционному ритейлу. Не рановато ли? Денис Викторов Опубликовано 04 февраля 2013«Software eats retail». На днях венчурный инвестор Марк Андриссен опять повторил свою коронную фразу. Те, кто до сих пор тратит время на развитие традиционных розничных
Проект Google Houses: городские скворечники в виде меток Google Maps Николай Маслухин
Проект Google Houses: городские скворечники в виде меток Google Maps Николай Маслухин Опубликовано 07 февраля 2013 Одна из самых узнаваемых интернет-иконок – красная капля-указатель сервиса Google Maps – возможно, станет символизировать единую сеть городских