4.1 Словарный процессор «OpenWriter»
4.1 Словарный процессор «OpenWriter»
И «Обязательный минимум...», и большинство конкретных учебных планов предусматривает знакомство лишь с базовой функциональностью программ манипуляции текстами, и любой из свободных словарных процессоров («AbiWord», «Kword», «OpenWriter») гарантированно и с избытком перекроет требования (так же, как и масса присутствующих на рынке несвободных программ, таких, как «Майкрософт Уорд», «Лексикон», «СтарОфис» или «УордПёрфект»). Поскольку большинство из них так или иначе развивают основные интерфейсные подходы «УордПёрфект», существенного (и могущего быть выявленным в пределах тех немногих часов, что учитель в состоянии уделить этой теме) эргономического различия между ними нет.
Значит основания для рационального выбора программы нужно искать не внутри темы манипулирования текстами, а в ее связи с другими учебными темами. У программистов есть такой эмпирический принцип: когда начинаешь путаться в программах, отложи их в сторону и попытайся разобраться со структурами данных — сам удивишься, насколько очевидными и простыми окажутся после этого решения, касающиеся программ. Возможно, этот принцип разумно применять и пользователям.
Давайте попробуем отложить в сторону программный инструментарий и разобраться с тем, какого рода данные мы им обрабатываем.
«Плоский» и размеченный
Водораздел между текстовыми редакторами и word-процессорами проходит по критерию способа отображения размеченного (имеющего некоторые атрибуты, такие, как цвет, начертание и кегль (размер) символов, выключка (выравнивание) и расположение абзацев, оформление страницы и т.п.) текста. Текстовый редактор отображает его как есть, например:
<курсив>Предложение, набранное курсивом.</курсив>
а word-процессор визуализирует эти атрибуты, например:
Предложение, набранное курсивом.
Визуализацию иногда путают с так называемым WYSIWYG-принципом (сокращение от «What you see is what you get» — «Что видишь, то и получишь»).
Однако в общем случае это неверно: WYSIWYG-идеология унаследована от эпохи персональных компьютеров, когда в ходе «малой компьютеризации» отдельные офисы и рабочие места становились «островами» безбумажных технологий в море бумажной коммуникации, и компьютерное представление мыслилось лишь промежуточной или предварительной формой существования текста или документа.
Сегодня большинство документов никогда не попадает на принтер, и нет нужды подстраиваться под архаичный бумажный документооборот. Вполне возможно, что автору или редактору удобнее выделение не курсивом, а подчеркиванием:
_Предложение,_набранное_курсивом._
Более того, современные технологии (например, HTML или XML-оформление текстов) изначально предполагают, что читатель документа может устанавливать собственные предпочтения в визуализации, зависящие от особенностей используемого им оборудования (размеров и разрешающей способности монитора и т.п.) или от своих биологических особенностей (слабого зрения, дальтонизма и т.п.), и в общем случае они могут не совпадать с предпочтениями автора или редактора.
Таким образом, один и тот же документ может быть отображен с разметкой, с визуализацией, а иногда — и с разметкой и с визуализацией (см. Рис. 4-1).
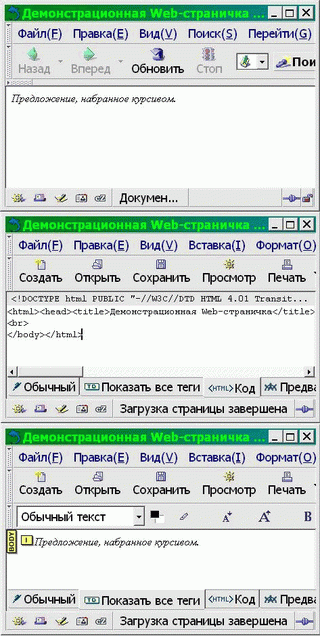
Рис 4-1
Хотя на рисунке нам удалось показать три типа отображения одного и того же документа, не выходя из одного прикладного пакета, это не такой частый случай. На самом деле текстовые редакторы, как правило, не имеют способности непосредственной визуализации вообще или обладают ею лишь в зачатке (как, например, Emacs, способный визуализировать формат Enriched text, но Emacs это не просто редактор, а целая операционная среда), а word-процессоры, в свою очередь, крайне неудобны для редактирования «плоского» текста: слишком разнятся базовая операторика и ожидаемая эргономика этих двух типов прикладных программ.
Учащийся сталкивается с задачей манипулирования «плоским» текстом как минимум два раза (при знакомстве с электронной почтой и при изучении основ программирования), соответственно, успевает познакомиться, как правило, с двумя разными текстовыми редакторами (встроенными в почтовую программу и среду программирования, соответственно). Как минимум два раза он сталкивается и с задачей манипулирования размеченным текстом: один раз его знакомят с word-процессором (как правило, в России под руку подворачивается «пиратский» «Майкрософт Уорд», либо бесплатно распространяемый «СтарОфис 5», либо дешевый «Лексикон», исключения единичны), а затем ему преподносят основы HTML.
Знакомство с манипулированием текстом, таким образом, оказывается бессистемным и фрагментарным, и, в лучшем случае, автор учебника или учитель сумеют рассказать о том, что сфера это, в общем-то единая, а показать это оказывается весьма затруднительно.
Значительным шагом к систематизации опыта, вырабатываемого школьным курсом, на наш взгляд, является использование инструментария, позволяющего демонстрировать возможность работы с размеченным текстом разными средствами. Это значит, что к очевидным требованиям, предъявляемым к «учебному» word-процессору (достаточность функций, локализованность, мультиплатформенность, ценовая доступность), добавляется серьезное пожелание: стандартность формата разметки.
Это сильно облегчает выбор. На самом деле, на сегодня всем перечисленным требованиям удовлетворяет, по сути, лишь одна программа. Но сначала — немного о стандартах.
Стандарты разметки текста
Существуют и доказали свою устойчивость два основных типа языков разметки.
Первый из них, это семейство, называемое *ML-языками: на эти две буквы заканчиваются аббревиатуры их названий — GML, SGML, HTML, XML, — а сами по себе эти буквы означают просто «markup language» — «язык разметки».
Второй — разработанный выдающимся американским теоретиком и практиком программирования Дональдом Кнутом язык программирования верстки TeX[68] и его расширения (например, LaTeX). Не будучи официальным стандартом, ТеХ постепенно вытесняет и замещает прочие языки разметки, предназначенные для набора и верстки текстов (TeX и системы на его основе плохо приспособлены для верстки т.н. «иллюстрированных изданий» с характерным для них богатым насыщением текста графикой, сложными обводами и наложениями текста на графику и пр., и этот сегмент рынка остается пока не стандартизованным).
За пределами этих типов — огромное множество нестандартных (и даже неопубликованных) форматов, зачастую использующих не текстовую, а двоичную форму представления данных (например, файлы «Майкрософт Уорд», «Лексикона» и т.п.). Это исключает возможность применения для работы с такими данными обычных текстовых редакторов и обработку их стандартными текстовыми утилитами, а также сильно затрудняет обратную разработку формата с целью обеспечения импорта и экспорта из независимо написанных программ[69].
Наверное, TeX имеет потенциал к использованию в качестве примера языка разметки (или, точнее, языка генерации разметки), однако вряд ли в средней школе — отчасти потому, что ориентирован на печатную форму в качестве окончательной формы представления содержания, что представляет на сегодня если не экзотическую, то, во всяком случае, достаточно специальную область применения компьютеров, в отличие от *ML-языков, в равной степени ориентированных и на «экран», и на «бумагу».
Судьба *ML-языков
SGML достаточно давно (с 1986 г.) является стандартом на разметку документов, принятым Международной организацией стандартизации (серия ISO 8879). Парадокс заключается в том, что до недавнего времени даже частичные реализации SGML были сравнительно немногочисленными, и его использование ограничивалось рамками государственных организаций (в массе своей оборонных и научных) и крупных корпораций. Гораздо более широкое распространение получили «похожие на SGML» языки, а именно, HTML различных версий, являющийся одним из технологических столпов WWW.
HTML был сознательно создан как «игрушечный SGML»: он не обладал всей гибкостью и мощью последнего, но был очень компактен и легок в реализации и изучении. Одна из сторон «игрушечности» HTML заключается в том, что он подталкивает пользователя к использованию физической, а не логической разметки, и именно поэтому, на наш взгляд, его не стоит изучать в школе.
Однако добавление все новых и новых возможностей и конструкций в HTML в ходе его развития привело к тому, что сложность его существенно выросла и приблизилась к сложности SGML-приложений, при сохраняющейся несовместимости с SGML.
Параллельное развитие двух близких по назначению языков было очевидно нецелесообразным, поэтому дальнейшее развитие WWW предполагает переход на XML — «расширяемый язык разметки», который превосходит по мощности, гибкости и согласованности HTML и является полноценным SGML-приложением. Уже сегодня наиболее развитые WWW-серверы генерируют HTML именно из XML; непосредственно «понимать» последний постепенно учатся и браузеры.
«Молодое поколение выбирает *ML!»
На наш взгляд, принципы расширяемой разметки, реализованные в XML, могут и должны стать одной из базовых составляющих компьютерной грамотности и обязательно должны найти свой путь в школьные учебные планы. Это позволит:
подвести единую основу и логически связать такие темы, как манипуляция размеченным текстом, гипертекстом и гипермедиа, векторной графикой, электронными таблицами и т.п.,
приблизить школьную информатику к реальным тенденциям развития информатики и информационной отрасли вообще, вывести ее из закутка «персонального компьютинга»,
упростить за счет стандартизации задачу выбора (разработки) учебных программ и пакетов.
Задача доступного изложения основ XML и приемов работы с ним сама по себе непроста, как дидактически, так и технически (в частности, нужны определения типов документов (DTD) для учебных задач, достаточно развитые для демонстрации возможностей языка, но в то же время достаточно простые для понимания XML-документов «с листа» и низкоуровневого редактирования).
Однако одно из основных препятствий на пути использования XML в школе — неразвитость визуализирующих редакторов — уже отпало с появлением офисного пакета «OpenOffice.org». Он сочетает привычные пользователям ПК пользовательские интерфейсы с поддержкой стандартных XML-приложений, таких, как «текстовый документ» (программа «OpenWriter»), «электронная таблица» («OpenCalc»), «презентация» (OpenImpess), «формула» (OpenMath), «гипертекст» (OpenWeb) и, что уже совсем не характерно для «офисного» софта, «векторный рисунок» («OpenDraw»), их взаимного внедрения и связывания.
По сути дела, «OO.o» — это «троянский конь», заброшенный в мир «малой компьютеризации»: «снаружи» он похож на «офис», а «изнутри» (или «с изнанки») представляет собой набор XML-инструментов. «Офисной» стороной он обращен к опыту пользователей персональных компьютеров, инструментальной — к современным, постперсональным вычислительно-коммуникационным системам (включая локальные сети и сети Интернет с возможностями безбумажного документооборота и совместной работы над документами).
«OpenWriter»
«OpenWriter» (далее — OW) — это неофициальное, но уже закрепляющееся название word-процессора из комплекта свободных офисных прикладных программ ОО.о (официальным названием, видимо, следует считать Ooowriter)[70].
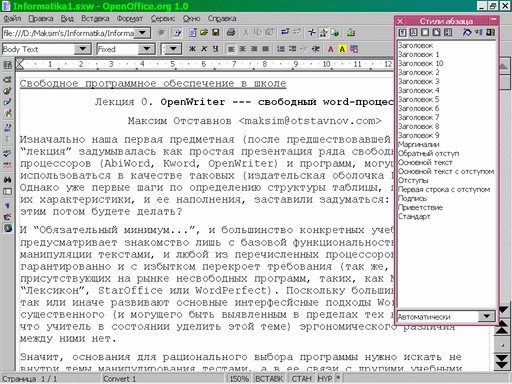
Рис. 4-2
Как уже говорилось выше, все словарные процессоры внешне (по функциональности и интерфейсу) похожи друг на друга, и OW (см. рисунок) — не исключение. Он предназначен для набора, редактирования и оформления текстов на естественных языках (включая многоязычные) и поддерживает:
физическое и логическое (через механизм стилей) форматирование документа в целом, отдельных страниц, разделов, абзацев и символов;
шаблоны (наборы стилей и формы документов);
лингвистическую поддержку (корректные переносы, проверку орфографии и грамматики, тезаурус (русского грамматического и тезаурус-модулей пока нет));
внедрение и связывание объектов — как из XML-приложений, так и чужеродных (включая растровую графику и результаты выполнения запросов к базам данных);
импорт/экспорт унаследованных нестандартных форматов (в базовую поставку входит модуль только для Microsoft Office), а также плоско-текстовых и гипертекстовых форматов;
встроенный макроязык;
автоматическую нумерацию элементов, оглавления и указатели;
... (назовите сами).
За подробностями отсылаю к[82].
Интересное, однако, начинается, когда мы посмотрим на OW «с изнанки». Файлы с расширением имени «.sfx», создаваемые им — это PKZIP-архивы, содержащие (в простейшем случае) набор XML-файлов, соответствующих (в терминах XML) манифесту, содержанию документов, определению стилей и значениям текущих настроек.
Заглянем в файл с содержанием (content.xml). Даже не зная XML, и лишь ориентируясь в синтаксисе языка разметки, можно понять, что файл содержит сначала определения стилей, использованных в документе (даже «жесткое» форматирование имитируется в OW путем создания неявных стилей), а затем размеченного указаниями на эти стили текста. Смотрите, заголовок статьи размечен так (Рис. 4-3).

Рис. 4-3
Понятно, что для форматирования использован один стиль абзаца «P2» и три стиля символов «T1», «T2» и «T3». Выше, в определениях стилей можно найти, что, допустим, «T2» — это стиль, определенный на Рис. 4-4.

Рис. 4-4
То есть «текстовый» (символьный) стиль, предполагающий набор и отображение полужирным шрифтом.
Теперь content.xml может обрабатываться любым XML-инструментом уже без использования «OO.o». Его можно преобразовать в HTML или проиндексировать, вывести на печать, просмотреть браузером, поддерживающим XML. Произвольные определения документов напрямую пока браузерами не поддерживаются, однако текст (неформатированный) можно уже сегодня просмотреть, просто открыв content.xml в «Мозилла» или другом браузере, поддерживающем XML.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
65-разрядный процессор?
65-разрядный процессор? В AS/400 ширина слова памяти возросла до 64 разрядов данных. С каждой восьмеркой байтов памяти AS/400 связан бит тега и указатель MI, занимающий два таких слова. В 1991 году нам виделись некоторые преимущества в том, чтобы хранить два теговых бита в регистрах
4.1 Словарный процессор «OpenWriter»
4.1 Словарный процессор «OpenWriter» И «Обязательный минимум...», и большинство конкретных учебных планов предусматривает знакомство лишь с базовой функциональностью программ манипуляции текстами, и любой из свободных словарных процессоров («AbiWord», «Kword», «OpenWriter»)
Глава 15 Словарный запас
Глава 15 Словарный запас Волож всегда отличался не только сильной харизмой, последовательностью в работе и жизни, склонностью к просчитанному риску и импровизации, а и умением стильно, к месту высказаться. И его высказывания — хороший мастер-класс для любого
Процессор
Процессор Центральный процессор компьютера – это именно тот компонент, на который ляжет основная нагрузка при обработке видео. При монтаже видео и рендеринге (rendering – просчет, значение этого термина будет раскрыто позже) в электронной начинке компьютера происходит
Центральный процессор
Центральный процессор Центральный процессор (ЦП, CPU, Central Processing Unit, «камень») – чип, выполняющий арифметические операции, заданные программами операционной системы и координирующий работу устройств компьютера. В ноутбуках используются специальные версии процессоров со
Процессор Xalan
Процессор Xalan Основные характеристики.? Платформы: Java, С++.? Расширения: функции и элементы расширения.? Полнота реализации: один из наиболее проработанных процессоров. ? Разработчик: Apache XML Project.? URL: http://xml.apache.org.Xalan — это очень известный XSLT-процессор, созданный в рамках Apache
Процессор Saxon
Процессор Saxon Основные характеристики.? Платформы: Java.? Расширения: функции и элементы расширения на Java.? Полнота реализации: практически идеальная.? Разработчик: Майкл Кей.? URL: http://saxon.sourceforge.net.XSLT-процессор Saxon был разработан и до сих пор поддерживается единственным
Процессор Sablotron
Процессор Sablotron Основные данные процессора.? Платформы: С++, Perl, PHP, Python.? Расширения: нет.? Полнота реализации: XSLT 1.0 и XPath 1.0 реализованы не полностью.? Разработчик: Ginger Alliance.? URL: http://www.gingerall.com.XSLT-процессор Sablotron, разработанный в Ginger Alliance, — это еще один пример весьма успешного
Процессор xt
Процессор xt Характеристики процессора.? Платформы: Java.? Расширения: функции расширения, некоторые элементы расширения.? Полнота реализации: практически полностью реализует XSLT версии PR-xslt-19991008.? Разработчик: Джеймс Кларк (James Clark).? URL: http://www.jclark.com/xml/xt.html.Без всякого
Процессор
Процессор Используемые в современных ноутбуках процессоры отличаются от устанавливаемых в стационарные системы. Некогда для уменьшения стоимости мобильные компьютеры строили на тех же процессорах, что и обычные, однако сейчас все производители отказались от такого
1.3.2. Процессор
1.3.2. Процессор Процессор — основное устройство, которое управляет работой компьютера и обрабатывает всю информацию. Процессор компьютера правильнее называть центральным процессором, по-английски — Central Processor Unit (CPU). В компьютерных кругах процессор часто сокращенно
Его величество Процессор!
Его величество Процессор! Мы уже говорили о процессорах, так ведь? Освежим память и вспомним, что процессор – это «мозг» компьютера, именно он обрабатывает информацию. Просто, но по существу. В этой главе в поисках знаний мы копнем несколько глубже, правда, придется
Процессор
Процессор Процессор (Central Processing Unit, CPU) – это один из основных компонентов компьютера, который выполняет арифметические и логические операции, заданные программой.Процессор (рис. 2.24) представляет собой интегральную микросхему (пластину кристаллического кремния
Процессор
Процессор Центральный процессор – самое нагруженное устройство компьютера, от скорости работы которого зависит общее быстродействие системы.В нормальных условиях процессор работает долго и без сбоев. После разгона его срок службы существенно сокращается. Главная
Процессор
Процессор О процессоре (рис. 3.1), несомненно, слышали все пользователи. Многие знают, что его основное предназначение – считать числа. Так, собственно, и есть. Если отбросить формальности, основная задача процессора (или ЦП – центрального процессора) заключается в