Жизненный путь процесса
Жизненный путь процесса
Процесс в UNIX создается системным вызовом fork(2). Процесс, сделавший вызов fork(2) называется родительским, а вновь созданный процесс — дочерним. Новый процесс является точной копией породившего его процесса. Как это ни удивительно, но новый процесс имеет те же инструкции и данные, что и его родитель. Более того, выполнение родительского и дочернего процесса начнется с одной и той же инструкции, следующей за вызовом fork(2). Единственно, чем они различаются — это идентификатором процесса PID. Каждый процесс имеет одного родителя, но может иметь несколько дочерних процессов.
Для запуска задачи, т.е. для загрузки новой программы, процесс должен выполнить системный вызов exec(2). При этом новый процесс не порождается, а исполняемый код процесса полностью замещается кодом запускаемой программы. Тем не менее окружение новой программы во многом сохраняется, в частности сохраняются значения переменных окружения, назначения стандартных потоков ввода/вывода, вывода сообщений об ошибках, а также приоритет процесса.
В UNIX запуск на выполнение новой программы часто связан с порождением нового процесса, таким образом сначала процесс выполняет вызов fork(2), порождая дочерний процесс, который затем выполняет exec(2), полностью замещаясь новой программой.
Рассмотрим эту схему на примере.
Допустим, пользователь, работая в командном режиме (в командном интерпретаторе shell) запускает команду ls(1). Текущий процесс (shell) делает вызов fork(2), порождая вторую копию shell. В свою очередь, порожденный shell вызывает exec(2), указывая в качестве параметра имя исполняемого файла, образ которого необходимо загрузить в память вместо кода shell. Код ls(1) замещает код порожденного shell, и утилита ls(1) начинает выполняться. По завершении работы ls(1) созданный процесс "умирает". Пользователь вновь возвращается в командный режим. Описанный процесс представлен на рис. 1.5. Мы также проиллюстрируем работу командного интерпретатора в примере, приведенном в главе 2.
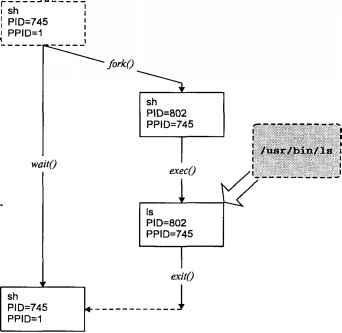
Рис. 1.5. Создание процесса и запуск программы
Если сделать "отпечаток" выполняемых процессов, например командой ps(1), между указанными стадиями, результат был бы следующим:
Пользователь работает в командном режиме:
UID PID PPID С STIME TTY TIME CMD
user1 745 1 10 10:11:34 ttyp4 0:01 sh
Пользователь запустил команду ls(1), и shell произвел вызов fork(2):
UID PID PPID С STIME TTY TIME CMD
user1 745 1 10 10:11:34 ttyp4 0:01 sh
user1 802 745 14 11:00:00 ttyp4 0:00 sh
Порожденный shell произвел вызов exec(2):
UID PID PPID С STIME TTY TIME CMD
user1 745 1 10 10:11:34 ttyp4 0:01 sh
user1 802 745 12 11:00:00 ttyp4 0:00 ls
Процесс ls(1) завершил работу:
UID PID PPID С STIME TTY TIME CMD
user1 745 1 10 10:11:34 ttyp4 0:01 sh
Описанная процедура запуска новой программы называется fork-and-exec.
Однако бывают ситуации, когда достаточно одного вызова fork(2) без последующего exec(2). В этом случае исполняемый код родительского процесса должен содержать логическое ветвление для родительского и дочернего процессов[9].
Все процессы в UNIX создаются посредством вызова fork(2). Запуск на выполнение новых задач осуществляется либо по схеме fork-and-exec, либо с помощью exec(2). "Прародителем" всех процессов является процесс init(1М), называемый также распределителем процессов. Если построить граф "родственных отношений" между процессами, то получится дерево, корнем которого является init(1M). Показанные на рис. 1.6 процессы sched и vhand являются системными и формально не входят в иерархию (они будут рассматриваться в следующих главах).
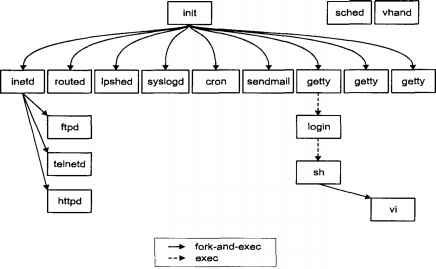
Рис. 1.6. Типичное "дерево" процессов в UNIX
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
12.1.1. Жизненный цикл сигнала
12.1.1. Жизненный цикл сигнала Сигналы имеют четко определенный жизненный цикл: они создаются, сохраняются до тех пор, пока ядро не выполнит определенное действие на основе сигнала, а затем вызывают совершение этого действия. Создание сигнала называют по-разному: поднятие
Догнать и удержать: жизненный цикл клиента в SEO — агентстве
Догнать и удержать: жизненный цикл клиента в SEO — агентстве С насыщением клиентского сегмента SEO — рынка перед любым агентством, словно тени забытых предков, встают вопросы проектного менеджмента и комплексной продажи услуг. Да так высоко встают, что грозят бросить тень
Путь Дзэн
Путь Дзэн Однако наиболее удачным и ярким представителем «пользовательской» линии развития Slackware суждено было стать дистрибутиву Zenwalk. Возникнув в середине 2004 года под именем Minislack, свое нынешнее имя он получил в начале второго года жизни – в августе 2005-го. И имя это
3.2. Жизненный цикл программы
3.2. Жизненный цикл программы Специфика программ как произведений не в том, что они «функциональны»3 и даже не в том, что пользование ими системно, а системы, образуемые программами при их сочетании между собой и оборудованием – динамичны4. Но если для прочих произведений
3.3. Жизненный цикл экземпляра программы и «общая стоимость владения» им
3.3. Жизненный цикл экземпляра программы и «общая стоимость владения» им Жизненный цикл отдельного экземпляра программы, находящегося в эксплуатации, вообще говоря, не совпадает с жизненным циклом самой программы как произведения5.В простейшем, вырожденном случае
14.12.4. Полный путь
14.12.4. Полный путь Когда вы запускаете какие-либо команды или программы, то необходимо указывать полный путь к ним. Большинство пользователей и администраторов просто указывают имя запускаемого объекта, что может стать причиной взлома. Да что там говорить, я сам грешу
7.3.2. Концепции, касающиеся основных средств производственного процесса организации Основные средства производственного процесса организации (ППО)
7.3.2. Концепции, касающиеся основных средств производственного процесса организации Основные средства производственного процесса организации (ППО) Организация устанавливает и сопровождает набор основных средств производственного процесса, как показано на рис. 4.1. К
Жизненный путь бага Джеймс Уиттакер
Жизненный путь бага Джеймс Уиттакер Баги напоминают детей, излишне опекаемых родителями. Они получают много внимания. Они рождаются в тиши IDE на машине разработчика, но как только они выходят в большой мир, их жизнь наполняют фанфары.Если тестировщик нашел баг, дальше его
«Путь Ruby»
«Путь Ruby» Что мы имеем и виду, творя о Пути Ruby? Я полагаю, что тут есть два взаимосвязанных аспекта: философия проектирования Ruby и философия использования этого языка. Естественно, что дизайн и применение связаны друг с другом, будь то программное или аппаратное
Путь к запущенному приложению
Путь к запущенному приложению Иногда требуется узнать путь к файлу запущенного приложения. Для этого можно воспользоваться кодом из листинга 14.3.Листинг 14.3using System.IO;using System.Reflection;txtAppDir.Text = Path.GetDirectoryName(Assembly.GetExecutingAssemblу().GetModule()[0]. FullyQuelifiedName).ToString();В этом примере после выбора
7.4. Путь к файлу
7.4. Путь к файлу Путь задает «маршрут» к файлу. Предположим, что у нас есть простенькое дерево каталогов: корневой каталог, каталог А, подкаталог Б, в котором находится файл foto.jpg. Путь к этому файлу будет выглядеть так:АБИногда нужно указать полное имя файла. Оно состоит из
Жизненный цикл сертификатов и ключей
Жизненный цикл сертификатов и ключей Политикой применения сертификатов должно быть четко определено, в какой момент времени сертификаты и ключи становятся валидными и как долго сохраняют свой статус, а также когда необходимо их заменять или восстанавливать.Важнейшим
Глава 21. Жизненный цикл идеального ХР-проекта
Глава 21. Жизненный цикл идеального ХР-проекта Идеальный проект ХР проходит сквозь короткую стадию начальной разработки, за которой следуют годы поддержки эксплуатации системы на производстве и одновременно пересмотра и переделки. Наконец, когда проект теряет