Голубятня: Ударим графематикой по графомании! Сергей Голубицкий
Голубятня: Ударим графематикой по графомании!
Сергей Голубицкий
Опубликовано 05 апреля 2012 года
Писатель: Я писатель!
Читатель: А по-моему, ты говно!
(Писатель стоит несколько минут, потрясённый этой новой идеей, и падает замертво. Его выносят.)
Даниил Хармс
Культур-повидлианствовать сегодня будем в пандан софтверному аппендиксу. В смысле, что не традиционный не пришей-к-красной-армии-рукав, а одно вытекает из другого, да и связано напрямую.
Разговор пойдет о разработке наших ученых-соотечественников, бороздящих ниву на стыке самых перспективных отраслей знания: структурно-прикладной лингвистики и компьютерных технологий.
Если с компьютерами вопросов, обычно, не возникает, то роль лингвиста почему-то в общественном сознании откровенно не дотягивает до заслуженного места. В лучшем случае, обывателю приходит в голову: переводчик какой-то! Если на пике славы, то — Гоблин. Больше ничего. Неужели придется дожидаться эпохи «Stargate» (помните еще культовый фильм Роланда Эммериха?), чтобы понять, что лингвист — это главный пророк нашей цивилизации (астролог, Дельфийский оракул и компьютерный томограф в одном флаконе!)?
Эк меня понесло! Короче говоря, один из разработчиков, Дмитрий Силницкий, зная о моих слабостях в сфере интерпретации смыслов и дата-майнинга, прислал на тестирование демо-версию совершенно уникального движка, который выполняет сравнительный анализ текстов по авторскому стилю и жанру.
При этом движок понятия не имеет о существовании автора имярек, да и вообще не догадывается о смысле слов и денотатах в принципе. Основа движка - графематический анализ, оперирующий лишь цепочками языковых символов - знаками, буквами и словоформами!
Для хотя бы приблизительного объяснения этого монстра позволю небольшую цитату из теоретического сопровождения разработок (текст Игоря Ножова из РГГУ):
«Основная цель графематического блока получить выборку полных словоформ из массива текстов базы данных. Графематический анализ работает с внешним представлением текста и использует таблицу стоп-слов. В этой таблице хранятся цифры, спецсимволы и частотные слова языка, нерелевантные для поиска по текстам.
Графематический анализ выполняет три функции:
1. отсечение стоп-слов в тексте;
2. разбиение данных на три потока;
3. индексация каждого потока.
Единицей графематического анализа является цепочка символов, выделенная с двух сторон пробелами. Выделенная цепочка символов подвергается последовательной обработке эвристическими правилами: отсечь знаки пунктуации, проверить присутствие гласных внутри цепочки, чередование верхнего и нижнего регистров и т.д. В зависимости от результатов обработки полученная цепочка символов направляется в один из трех потоков данных:
- цифровые и символьные комплексы (‘кг’, ‘ст.’, ’12.01.99’);
- аббревиатуры — названия государств, организаций, предприятий (‘СССР’, ‘ЮНЕСКО’, ‘ДорСтройСервис’);
- полные словоформы»
В результате столь необычного и внешне совершенно схоластического анализа мы получаем более, чем осмысленные результаты. Именно созерцание практических результатов произвело на меня неизгладимое впечатление.
Я получил демо-версии аналитического движка для двух баз данных. Первая — англоязычная — проводила стилистический и жанровый анализ относительно хоть и скромной, но вполне репрезентативного массива данных, насчитывающего 2995 авторов и 6266 произведений. Вторая — русскоязычная — чисто номинальная — лишь 700 книг авторов, выражающих мысли на великом и могучем.
Естественно я начал тестирование с себя любимого: ввел в анализатор текст книги «Как зовут вашего бога». На выходе получил такой результат:

Как видите графематический анализатор опознал мой стиль почти с абсолютной точностью — коэффициент корреляции 95,84 %! Далее идет Вильгельм Адам (кто это?) и много всяких незнакомых товарищей — вплоть до Ильфа и Петрова (62,70 %) и Михаила Веллера (42,66%).
Проверим теперь анализатор на коротких текстах — ввожу «Дело русских медведей», то есть одну из последних Голубятен:
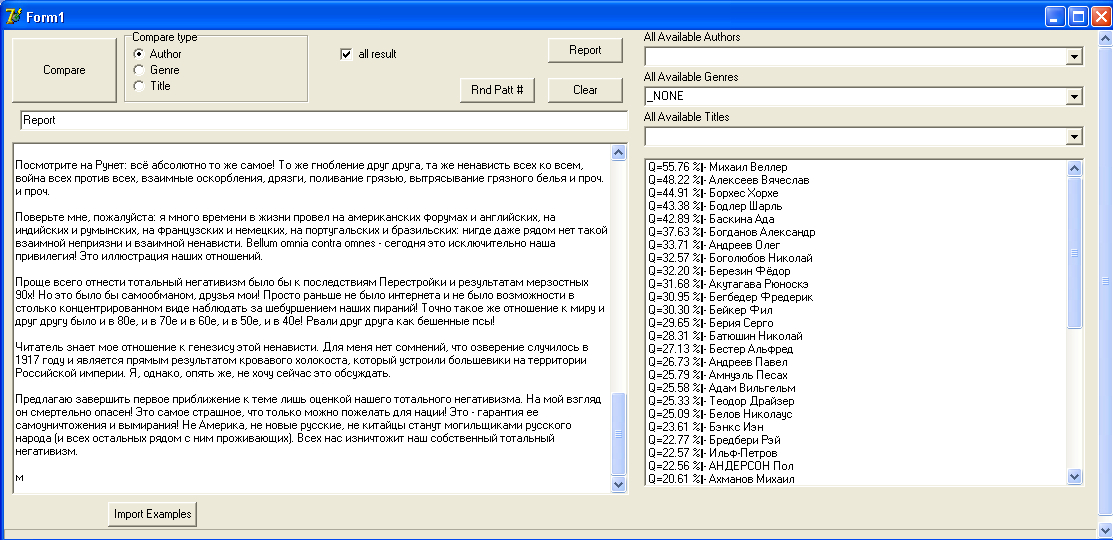
Забавно, не правда ли? Корреляция с самим собой пропала, что не удивительно: на 5 тысячах знаков никакой глубины ожидать не приходится. Зато всплыли чужие ассоциации. Так мой сегодняшний стиль демонстрирует самый высокий коэффициент стилистической и жанровой корреляции с Михаилом Веллером (55,76 %). Далее следует Вячеслав Алексеев (это кто?), Хорхе Луис Борхес (я старался!), Шарль Бодлер (откуда анализатор знает про моего самого любимого поэта?!) и т.д. Даже обожаемый Аутагава Рюноскэ присутствует в первой десятке корреляции!
Тысяча чертей: но ведь это же не в бровь, а в самый глаз!
Как и полагается, честному смекалкину, советского замеса, я тут же захотелось всунуть лом между приводной цепью и шестернями анализатора, поэтому скормил ему голубятню образца 2004 года («Лингвистический анализ одного отстойника: призраки ФИДО в XXI веке»)!
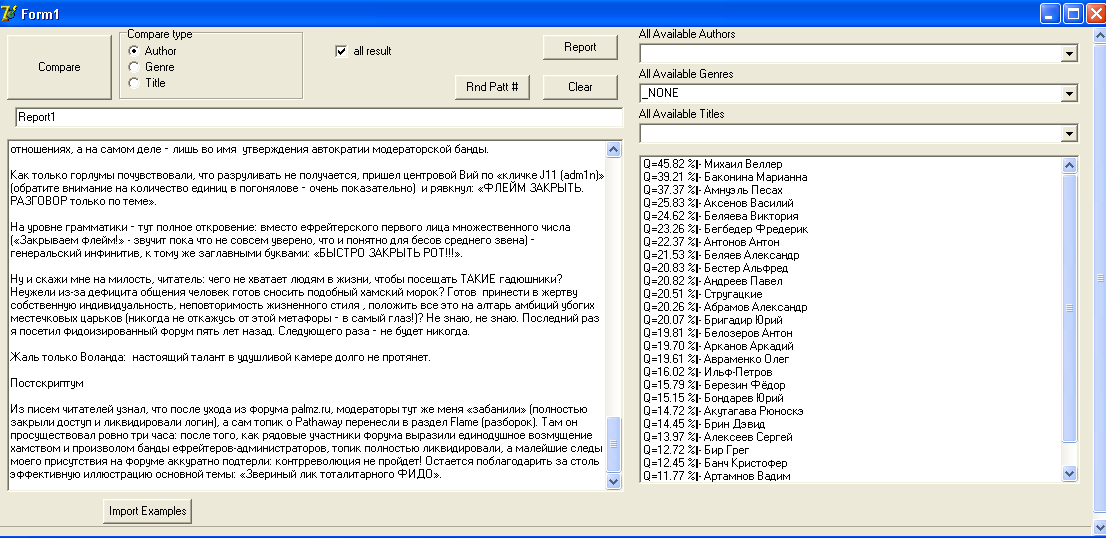
Опять нет прямой корреляции с автором, но подтвердился Веллер на первом месте. И Рюноскэ. Зато исчез Бодлер (старею?).
Признаюсь, результат сразил меня наповал. Понимаете, в чем дело: я же очень хорошо знаю креативные импульсы, наполняющие мои тексты. Меняется рациональное осмысление письма, его техника, приемы, стилистические фигуры и уловки, но стилистическую основу изменить нельзя — она сидит глубоко в подсознании! И там у меня — кладезь морализма, детского идеализма, романтизма, замешанного на трагичном восприятии жизни. Рюноскэ и Бодлер — очень точное описание моих чувств, преломленных через создаваемые тексты. Плюс - l’art naif на уровне семантики, синтаксиса, подбора метафор.
Все эти довольно своеобразные жанровые и стилистические особенности моих текстов, отделенных друг от друга 9 годами, графематический анализатор уловил поразительным образом! Не зная ни имен, ни культурологических контекстов автора! Не говоря уже о консистентности стиля и жанра во времени (9 лет дистанции все-таки!). Потрясающе!
Ради чистоты эксперимента подверг жанрово-стилистическому анализу текст Михаила Веллера («Легенды Арбата»):
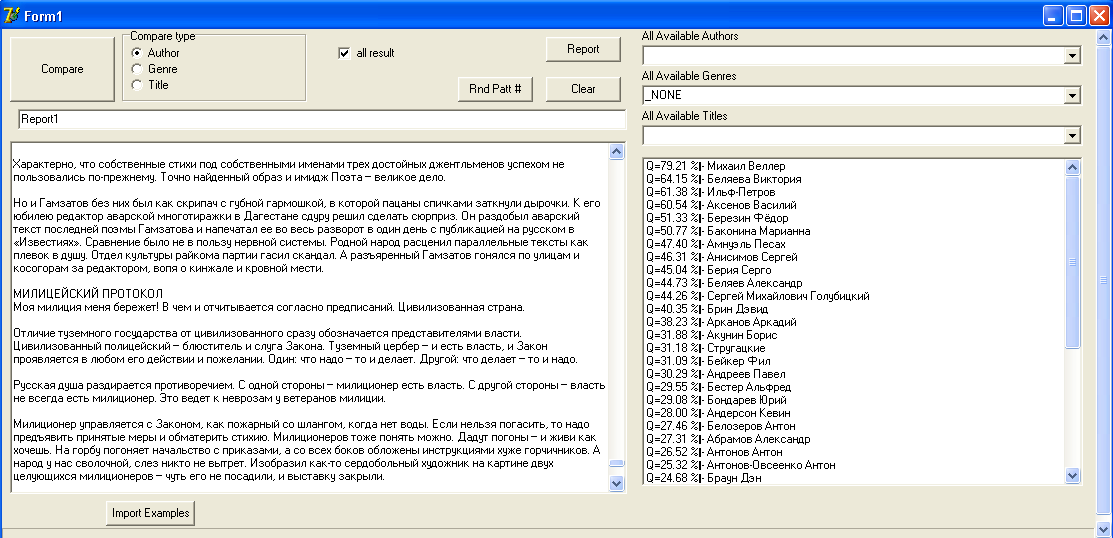
Текст большой, поэтому анализатор безупречно определяет первым в списке самого автора! Забавно, что Сергей Михайлович Голубицкий числится в корреляционном списке Веллера под номером 11 (44,26 %)! Вот она — диалектика взаимовлияния :)
Теперь — Юрий Бондарев («Берег»):
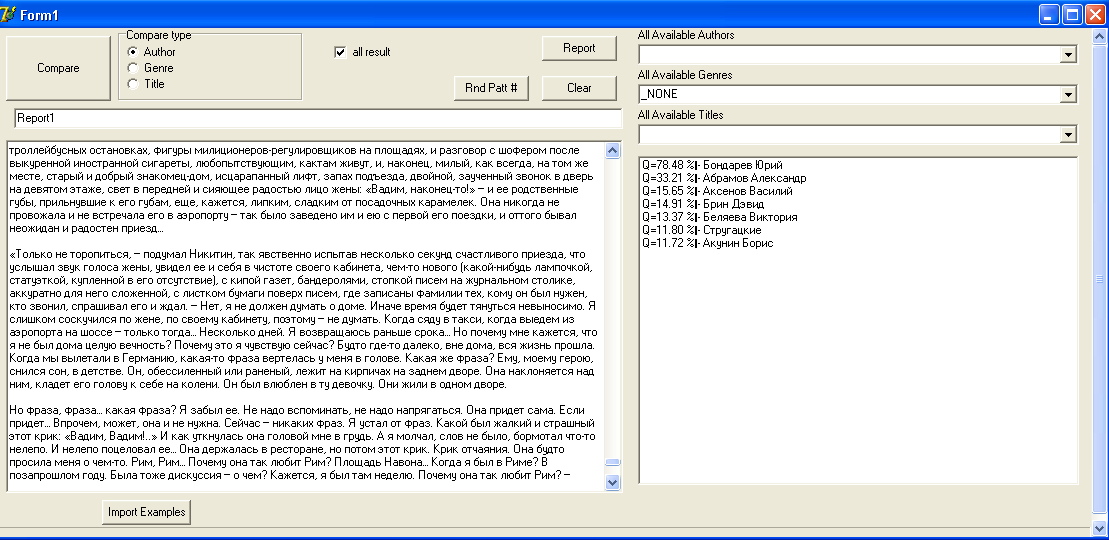
И тот же результат — первым в списке корреляций — сам автор (78,48 %), далее следуют Александр Абрамов, Василий Аксенов, Стругацкие, Акунин.
Дмитрий Силницкий со товарищи трезво отдают себе отчет о непомерной работе, которая предстоит до того, чтобы придать концепту сколько-нибудь практический (не говоря о товарном!) вид. Самое, однако, главное, что уже сейчас четко вырисовываются как минимум несколько аспектов применения этой разработки: во-первых, на основе графематического анализатора можно создать платформу для продвижения неизвестных авторов и разработать систему книжных рекомендаций; во-вторых, можно построить интеллектуальный журнал типа ZITE, который будет задействовать совершенно иные критерии для кастомизации потребительского контента (жанрово-стилистические — и это мне кажется будет посильнее Фауста Гете на фоне современного чисто тематического — «топики» и «лайки» — подхода); в-третьих, можно будет разработать самые разнообразные системы для тестирования и типизирования личности.
И это — лишь на поверхности. Лингвистические методы анализа действительности столь обширны и универсальны, что навскидку даже затрудняюсь обозначить хоть приблизительно глобальные сферы применения. Психологическая (и психиатрическая) терапия? Извольте! Дата-майнинг стратегического назначения? Не вопрос! Банальная информационная разведка? You bet! Полиграф? Да вот он — уже тут! Ну и так далее.
Короче говоря, я радуюсь, что так много жизни пульсирует вокруг и не все еще потеряно!
К оглавлению
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Голубятня: Ась? Сергей Голубицкий
Голубятня: Ась? Сергей Голубицкий Опубликовано 12 октября 2010 года Читатели со стажем не дадут соврать: о системах распознания речи (VRS, Voice Recognition Systems) я писал регулярно, начиная с самой первой статьи, опубликованной в бумажной «Компьютерре» аж в 1996
Голубятня: Шаньчжай Сергей Голубицкий
Голубятня: Шаньчжай Сергей Голубицкий Опубликовано 20 апреля 2011 года Сегодня у нас обзорный пост, предваряющий целый букет видеопрезентаций, которые прольются на читательские головы, начиная со следующей недели. У меня скопилось в ожидании
Голубятня: I Am You Сергей Голубицкий
Голубятня: I Am You Сергей Голубицкий Праздник «Холи» возбудил не только гоанцев, но и всю творчески активную тусовку европейского десанта. Надо сказать, что в Гоа постоянно проживает значительное количество музыкантов, художников, поэтов и танцоров, которые работают, не
Голубятня: Что еще? Сергей Голубицкий
Голубятня: Что еще? Сергей Голубицкий Опубликовано 25 июня 2011 года На мартовской презентации айпада Garage Band явился, как говориться, story apart. Не удивительно, что в среде профессиональных музыкантов и композиторов, познакомившихся с уникальными и
Голубятня: PX Сергей Голубицкий
Голубятня: PX Сергей Голубицкий На следующей неделе у меня будет большая съемка в передаче «Крипто» («Совершенно секретно»), посвященной «Филадельфийскому эксперименту». Казалось бы — ну что еще можно высосать интересного из этого замшелого сюжета в наши
Сергей Голубицкий Голубятня: Нефилимы
Сергей Голубицкий Голубятня: Нефилимы «И случилось, — после того как сыны человеческие умножились в те дни, у них родились красивые и прелестные дочери. И ангелы, сыны неба, увидели их, и возжелали их, и сказали друг другу: «Давайте выберем себе жен в среде сынов
Голубятня: Just 5 Сергей Голубицкий
Голубятня: Just 5 Сергей Голубицкий Опубликовано 12 января 2011 года Продолжаем новогодний видео марафон. Сегодня вертим в руках телефоны второго поколения от Just 5. В видео клипе я назвал сотрудников этой удачливой компании «нашими соотечественниками»
Голубятня: Out-of-the-box Сергей Голубицкий
Голубятня: Out-of-the-box Сергей Голубицкий Опубликовано 24 августа 2010 года Концепция out-of-the-box хорошо известна шозистам мира, хотя и не особо принята в нашем айтишном королевстве. Смысл концепции прост: распаковал коробку, достал и сразу же начал
Голубятня: Сергей Комаров Сергей Голубицкий
Голубятня: Сергей Комаров Сергей Голубицкий Опубликовано 15 июля 2010 года Очередной микроюбилей — 200 публикация «Голубятни Онлайн». Вспоминаю бумажные «Голубятню 100», «Голубятню 200», «Голубятню 300», «Голубятню 400»! Надеялся дожить до совсем уж
Голубятня: АК-47 Сергей Голубицкий
Голубятня: АК-47 Сергей Голубицкий Опубликовано 16 июня 2010 года Пауза, вызванная традиционным летним анабазисом на юга, затянулась, поэтому беру стахановские обязательства: до конца месяца выдавать посты в удвоенном ритме! Тем более, что совсем без
Голубятня: Какодемон Сергей Голубицкий
Голубятня: Какодемон Сергей Голубицкий Опубликовано 15 марта 2011 года Александр Звягин — один из главных многолетних поставщиков захватывающей сенсационно-конспирологической фактуры на мой приватный email — поделился вчера личными размышлениями
Голубятня: Антигаец Сергей Голубицкий
Голубятня: Антигаец Сергей Голубицкий Опубликовано 26 июня 2012 года Сегодня мой рассказ об удивительном гаджете по имени Escort Passport 9500ix International. По названию абсолютно невозможно догадаться, о чем идет речь, поэтому расшифровываю: это радар-детектор,
Голубятня: КГ/АМ Сергей Голубицкий
Голубятня: КГ/АМ Сергей Голубицкий Опубликовано 26 марта 2012 года Повидло у меня сегодня слегка не первой свежести, но не беда: сладкий продукт не тухнет :) Тем более, что хочу предложить читателям довольно непривычный аспект хорошо знакомой
Голубятня: Ударим графематикой по графомании!
Голубятня: Ударим графематикой по графомании! Автор: Сергей ГолубицкийОпубликовано 05 апреля 2012 года Писатель: Я писатель! Читатель: А по-моему, ты говно! (Писатель стоит несколько минут, потрясённый этой новой идеей, и падает замертво. Его выносят.) Даниил