1.2. Определение количества информации. Единицы измерения количества информации
1.2. Определение количества информации. Единицы измерения количества информации
Как уже отмечалось, понятие информации можно рассматривать при различных ограничениях, накладываемых на ее свойства, т. е. при различных уровнях рассмотрения. В основном выделяют три уровня – синтаксический, семантический и прагматический. Соответственно на каждом из них для определения количества информации применяют различные оценки.
На синтаксическом уровне для оценки количества информации используют вероятностные методы, которые принимают во внимание только вероятностные свойства информации и не учитывают другие (смысловое содержание, полезность, актуальность и т. д.). Разработанные в середине XX в. математические и, в частности, вероятностные методы позволили сформировать подход к оценке количества информации как к мере уменьшения неопределенности знаний. Такой подход, называемый также вероятностным, постулирует принцип: если некоторое сообщение приводит к уменьшению неопределенности наших знаний, то можно утверждать, что такое сообщение содержит информацию. При этом сообщения содержат информацию о каких-либо событиях, которые могут реализоваться с различными вероятностями. Формулу для определения количества информации для событий с различными вероятностями и получаемых от дискретного источника информации предложил американский ученый К. Шеннон в 1948 г. Согласно этой формуле количество информации может быть определено следующим образом:

где I – количество информации; N – количество возможных событий (сообщений); pi – вероятность отдельных событий (сообщений); ? – математический знак суммы чисел.
Определяемое с помощью формулы (1.1) количество информации принимает только положительное значение. Поскольку вероятность отдельных событий меньше единицы, то соответственно выражение log^,– является отрицательной величиной и для получения положительного значения количества информации в формуле (1.1) перед знаком суммы стоит знак минус.
Если вероятность появления отдельных событий одинаковая и они образуют полную группу событий, т. е.
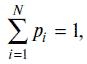
то формула (1.1) преобразуется в формулу Р. Хартли:

В формулах (1.1) и (1.2) отношение между количеством информации и соответственно вероятностью, или количеством, отдельных событий выражается с помощью логарифма. Применение логарифмов в формулах (1.1) и (1.2) можно объяснить следующим образом. Для простоты рассуждений воспользуемся соотношением (1.2). Будем последовательно присваивать аргументу N значения, выбираемые, например, из ряда чисел: 1, 2, 4, 8, 16, 32, 64 и т. д. Чтобы определить, какое событие из N равновероятных событий произошло, для каждого числа ряда необходимо последовательно производить операции выбора из двух возможных событий. Так, при N = 1 количество операций будет равно 0 (вероятность события равна 1), при N = 2, количество операций будет равно 1, при N = 4 количество операций будет равно 2, при N = 8, количество операций будет равно 3 и т. д. Таким образом получим следующий ряд чисел: 0, 1, 2, 3, 4, 5, 6 и т. д., который можно считать соответствующим значениям функции I в соотношении (1.2). Последовательность значений чисел, которые принимает аргумент N, представляет собой ряд, известный в математике как ряд чисел, образующих геометрическую прогрессию, а последовательность значений чисел, которые принимает функция I, будет являться рядом, образующим арифметическую прогрессию. Таким образом, логарифм в формулах (1.1) и (1.2) устанавливает соотношение между рядами, представляющими геометрическую и арифметическую прогрессии, что достаточно хорошо известно в математике.
Для количественного определения (оценки) любой физической величины необходимо определить единицу измерения, которая в теории измерений носит название меры. Как уже отмечалось, информацию перед обработкой, передачей и хранением необходимо подвергнуть кодированию. Кодирование производится с помощью специальных алфавитов (знаковых систем). В информатике, изучающей процессы получения, обработки, передачи и хранения информации с помощью вычислительных (компьютерных) систем, в основном используется двоичное кодирование, при котором используется знаковая система, состоящая из двух символов 0 и 1. По этой причине в формулах (1.1) и (1.2) в качестве основания логарифма используется цифра 2.
Исходя из вероятностного подхода к определению количества информации эти два символа двоичной знаковой системы можно рассматривать как два различных возможных события, поэтому за единицу количества информации принято такое количество информации, которое содержит сообщение, уменьшающее неопределенность знания в два раза (до получения событий их вероятность равна 0,5, после получения – 1, неопределенность уменьшается соответственно: 1/0,5 = 2, т. е. в 2 раза). Такая единица измерения информации называется битом (от англ. слова binary digit – двоичная цифра). Таким образом, в качестве меры для оценки количества информации на синтаксическом уровне, при условии двоичного кодирования, принят один бит.
Следующей по величине единицей измерения количества информации является байт, представляющий собой последовательность, составленную из восьми бит, т. е.
1 байт = 23 бит = 8 бит.
В информатике также широко используются кратные байту единицы измерения количества информации, однако в отличие от метрической системы мер, где в качестве множителей кратных единиц применяют коэффициент 10n, где п = 3, 6, 9 и т. д., в кратных единицах измерения количества информации используется коэффициент 2n. Выбор этот объясняется тем, что компьютер в основном оперирует числами не в десятичной, а в двоичной системе счисления.
Кратные байту единицы измерения количества информации вводятся следующим образом:
1 Килобайт (Кбайт) = 210 байт = 1024 байт,
1 Мегабайт (Мбайт) = 210 Кбайт = 1024 Кбайт,
1 Гигабайт (Гбайт) = 210 Мбайт = 1024 Мбайт,
1 Терабайт (Тбайт) = 210 Гбайт = 1024 Гбайт,
1 Петабайт (Пбайт) = 210 Тбайт = 1024 Тбайт,
1 Экзабайт (Эбайт) = 210 Пбайт = 1024 Пбайт.
Единицы измерения количества информации, в названии которых есть приставки «кило», «мега» и т. д., с точки зрения теории измерений не являются корректными, поскольку эти приставки используются в метрической системе мер, в которой в качестве множителей кратных единиц используется коэффициент 10n, где п = 3, 6, 9 и т. д. Для устранения этой некорректности международная организацией International Electrotechnical Commission, занимающаяся созданием стандартов для отрасли электронных технологий, утвердила ряд новых приставок для единиц измерения количества информации: киби (kibi), меби (mebi), гиби (gibi), теби (tebi), пети (peti), эксби (exbi). Однако пока используются старые обозначения единиц измерения количества информации, и требуется время, чтобы новые названия начали широко применяться.
Вероятностный подход используется и при определении количества информации, представленной с помощью знаковых систем. Если рассматривать символы алфавита как множество возможных сообщений N, то количество информации, которое несет один знак алфавита, можно определить по формуле (1.1). При равновероятном появлении каждого знака алфавита в тексте сообщения для определения количества информации можно воспользоваться формулой (1.2).
Количество информации, которое несет один знак алфавита, тем больше, чем больше знаков входит в этот алфавит. Количество знаков, входящих в алфавит, называется мощностью алфавита. Количество информации (информационный объем), содержащееся в сообщении, закодированном с помощью знаковой системы и содержащем определенное количество знаков (символов), определяется с помощью формулы:

где V – информационный объем сообщения; / = log2N, информационный объем одного символа (знака); К – количество символов (знаков) в сообщении; N – мощность алфавита (количество знаков в алфавите).
Поясним вышесказанное в п. 1.2 на примерах.
Пример 1.1
Определим, какое количество информации можно получить после реализации одного из шести событий. Вероятность первого события составляет 0,15; второго – 0,25; третьего – 0,2; четвертого – 0,12; пятого – 0,12; шестого – 0,1, т. е. Р1 = 0,15; Р2 = 0,25; Р3 = 0,2; Р4 = 0,18; Р5 = 0,12; Р6 = 0,1.
Решение.
Для определения количества информации применим формулу (1.1)
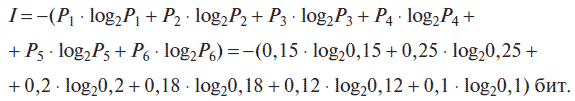
Для вычисления этого выражения, содержащего логарифмы, воспользуемся сначала компьютерным калькулятором, а затем табличным процессором Microsoft (MS) Excel, входящим в интегрированный пакет программ MS Office ХР.
Для вычисления с помощью компьютерного калькулятора выполним следующие действия.
С помощью команды: [Кнопка Пуск – Программы – Стандартные – Калькулятор] запустим программу Калькулятор. После запуска программы выполним команду: [Вид – Инженерный] (рис. 1.3).
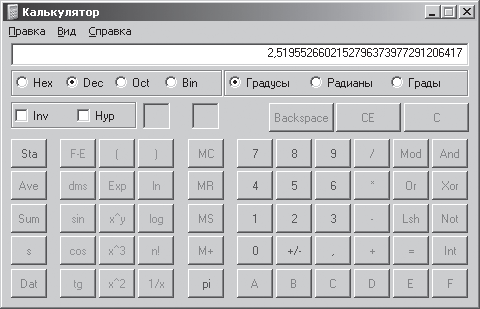
Рис. 1.3. Инженерный калькулятор
Кнопка log калькулятора производит вычисление десятичного (по основанию 10) логарифма отображаемого числа. Поскольку в нашем случае необходимо производить вычисления логарифмов по основанию 2, а данный калькулятор не позволяет этого делать, то необходимо воспользоваться известной формулой:
logbN = М · logaN,
где
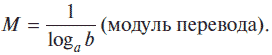
В нашем случае соотношение примет вид: log2N = M log10N,
где
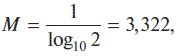
т. е log2N = 3,322 · log10N, и выражение для вычисления количества информации примет вид:
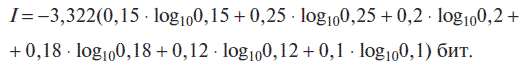
При вычислении на калькуляторе используем кнопки: +/- (изменение знака отображаемого числа),() (открывающие и закрывающие скобки), log (логарифм числа по основанию 10) и т. д. Результат вычисления показан на рис. 1.3. Таким образом, количество информации I = 2,52 бит.
Воспользуемся теперь табличным процессором MS Excel. Для запуска программы Excel выполним команду: [Кнопка Пуск – Программы – MS Office ХР – Microsoft Excel]. В ячейки А1, В1, С1, D1, E1, F1 открывшегося окна Excel запишем буквенные обозначения вероятностей Р1, Р2, P3, Р4, P5, P6 а в ячейку G1 – количество информации I, которое необходимо определить. Для написания нижних индексов у вероятностей Р1 ? P6 в ячейках А1, В1, С1, D1, E1, F1 выполним следующую команду: [Формат – Ячейки – Шрифт – Видоизменение (поставим флажок напротив нижнего индекса) ]. В ячейки А2, В2, С2, D2, Е2, F2 запишем соответствующие значения вероятностей.
После записи значений в ячейки необходимо установить в них формат числа. Для этого необходимо выполнить следующую команду: [Формат – Ячейки – Число – Числовой (устанавливаем число десятичных знаков, равное двум) ]. Устанавливаем в ячейке G2 тот же числовой формат. В ячейку G2 записываем выражение = – (A2*LOG(A2;2) + B2*LOG(B2;2) + C2*LOG(C2;2) + D2*LOG(D2;2) + E2*LOG(E2;2) + F2*LOG(F2;2) ). После нажатия на клавиатуре компьютера клавиши <Enter>, в ячейке G2 получим искомый результат – I = 2,52 бит (рис. 1.4).
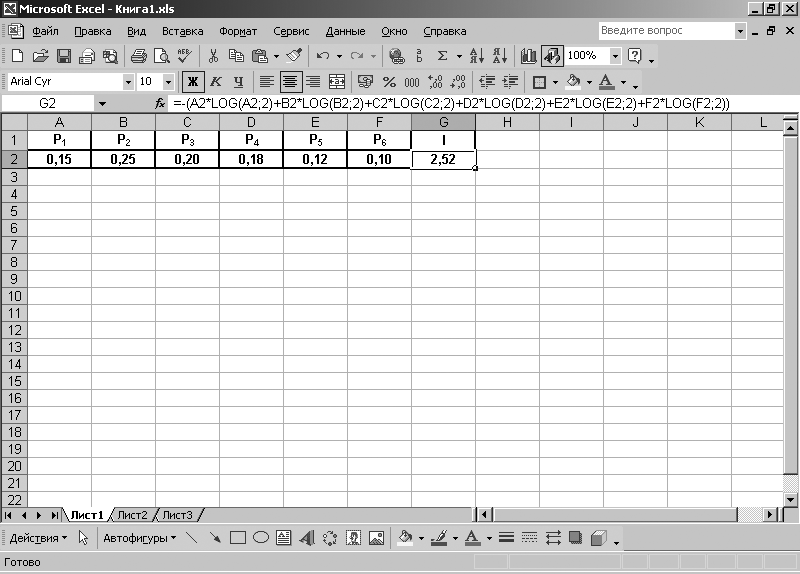
Рис. 1.4. Результат вычисления количества информации
Пример 1.2
Определим, какое количество байт и бит информации содержится в сообщении, если его объем составляет 0,25 Кбайта.
Решение.
С помощью калькулятора определим количество байт и бит информации, которое содержится в данном сообщении:
I = 0,25 Кбайт · 1024 байт/1 Кбайт = 256 байт;
I = 256 байт · 8 бит/1 байт = 2048 бит.
Пример 1.3
Определим мощность алфавита, с помощью которого передано сообщение, содержащее 4096 символов, если информационный объем сообщения составляет 2 Кбайта.
Решение.
С помощью калькулятора переведем информационный объем сообщения из килобайт в биты:
V = 2 Кбайт 1024 байт/1 Кбайт = 2048 байт 8 бит/1 байт = 16384 бит.
Определим количество бит, приходящееся на один символ (информационный объем одного символа) в алфавите:
I = 16 384 бит/4096 = 4 бит.
Используя формулу (1.3), определим мощность алфавита (количество символов в алфавите) :
N = 2I = 24 = 16.
Как уже отмечалось, если принять во внимание только свойство информации, связанное с ее смысловым содержанием, то при определении понятия информации можно ограничиться смысловым, или семантическим, уровнем рассмотрения этого понятия.
На семантическом уровне информация рассматривается по ее содержанию, отражающему состояние отдельного объекта или системы в целом. При этом не учитывается ее полезность для получателя информации. На данном уровне изучаются отношения между знаками, их предметными и смысловыми значениями (см. рис. 1.1), что позволяет осуществить выбор смысловых единиц измерения информации. Поскольку смысловое содержание информации передается с помощью сообщения, т. е. в виде совокупности знаков (символов), передаваемых с помощью сигналов от источника информации к приемнику, то широкое распространение для измерения смыслового содержания информации получил подход, основанный на использовании тезаурусной меры. При этом под тезаурусом понимается совокупность априорной информации (сведений), которой располагает приемник информации.
Данный подход предполагает, что для понимания (осмысливания) и использования полученной информации приемник (получатель) должен обладать априорной информацией (тезаурусом), т. е. определенным запасом знаков, наполненных смыслом, слов, понятий, названий явлений и объектов, между которыми установлены связи на смысловом уровне. Таким образом, если принять знания о данном объекте или явлении за тезаурус, то количество информации, содержащееся в новом сообщении о данном предмете, можно оценить по изменению индивидуального тезауруса под воздействием данного сообщения. В зависимости от соотношений между смысловым содержанием сообщения и тезаурусом пользователя изменяется количество семантической информации, при этом характер такой зависимости не поддается строгому математическому описанию и сводится к рассмотрению трех основных условий, при которых тезаурус пользователя:
• стремится к нулю, т. е. пользователь не воспринимает поступившее сообщение;
• стремится к бесконечности, т. е. пользователь досконально знает все об объекте или явлении и поступившее сообщение его не интересует;
• согласован со смысловым содержанием сообщения, т. е. поступившее сообщение понятно пользователю и несет новые сведения.
Два первых предельных случая соответствуют состоянию, при котором количество семантической информации, получаемое пользователем, минимально. Третий случай связан с получением максимального количества семантической информации. Таким образом, количество семантической информации, получаемой пользователем, является величиной относительной, поскольку одно и то же сообщение может иметь смысловое содержание для компетентного и быть бессмысленным для некомпетентного пользователя.
Поэтому возникает сложность получения объективной оценки количества информации на семантическом уровне ее рассмотрения и для получения такой оценки используют различные единицы измерения количества информации: абсолютные или относительные. В качестве абсолютных единиц измерения могут использоваться символы, реквизиты, записи и т. д., а в качестве относительной – коэффициент содержательности, который определяется как отношение семантической информации к ее объему. Например, для определения на семантическом уровне количества информации, полученной студентами на занятиях, в качестве единицы измерения может быть принят исходный балл (символ), характеризующий степень усвояемости ими нового учебного материала, на основе которого можно косвенно определить количество информации, полученное каждым студентом. Это количество информации будет выражено через соответствующий оценочный балл в принятом диапазоне оценок.
При семантическом подходе к оценке количества информации и выборе единицы измерения существенным является вид получаемой информации (сообщения). Так, данный подход к оценке количества экономической информации позволяет выявить составную единицу экономической информации, состоящую из совокупности других единиц информации, связанных между собой по смыслу. Элементарной составляющей единицей экономической информации является реквизит, т. е. информационная совокупность, которая не поддается дальнейшему делению на единицы информации на смысловом уровне. Деление реквизитов на символы приводит к потере их смыслового содержания. Каждый реквизит характеризуется именем, значением и типом. При этом под именем реквизита понимается его условное обозначение, под значением – величина, характеризующая свойства объекта или явления в определенных обстоятельствах, под типом – множество значений реквизита, объединенных определенными признаками и совокупностью допустимых преобразований.
Реквизиты принято делить на реквизиты-основания и реквизиты-признаки [2].
Реквизиты-основания характеризуют количественную сторону экономического объекта, процесса или явления, которые могут быть получены в результате совершения отдельных операций – вычислений, измерений, подсчета натуральных единиц и т. д. В экономических документах к ним можно отнести, например, цену товара, его количество, сумму и т. п. Реквизиты-основания чаще всего выражаются в цифрах, над которыми могут выполняться математические операции.
Реквизиты-признаки отражают качественные свойства экономического объекта, процесса или явления. С помощью реквизитов-признаков сообщения приобретают индивидуальный характер. В экономических документах к ним можно отнести, например, номер документа, имя отправителя, дату составления документа, вид операции и т. п. Реквизиты-признаки позволяют осуществлять логическую обработку единиц количества информации на семантическом уровне: поиск, выборку, группировку, сортировку и т. д.
Отдельный реквизит-основание вместе с относящимися к нему реквизитами-признаками образует следующую в иерархическом отношении составную единицу экономической информации – показатель. Показатель имеет наименование, в состав которого входят термины, обозначающие измеряемый объект: себестоимость, затраты, мощность, прибыль и т. д. Кроме того, показатель содержит формальную характеристику и дополнительные признаки. К формальной характеристике относится способ его получения (объем, сумма, прирост, процент, среднее значение и т. д.), а к дополнительным – пространственно-временные (где находится измеряемый объект, время, к которому относится данный показатель) и метрологические (единицы измерения).
Таким образом, с помощью совокупности реквизитов и соответствующих им показателей можно оценить количество экономической информации, получаемой от исследуемого объекта (источника информации).
Кроме подхода, основанного на использовании тезаурусной меры, при определении количества информации на семантическом уровне находят применение и другие подходы [1]. Например, один из подходов, связанных с семантической оценкой количества информации, заключается в том, что в качестве основного критерия семантической ценности информации, содержащейся в сообщении, принимается количество ссылок на него в других сообщениях. Количество получаемой информации определяется на основе статистической обработки ссылок в различных выборках.
Подводя итог сказанному, можно утверждать, что существовала и существует проблема формирования единого системного подхода к определению информации на семантическом уровне. Это подтверждается и тем, что в свое время для создания строгой научной теории информации К. Шеннон вынужден был отбросить важное свойство информации, связанное со смысловым ее содержанием.
Кроме перечисленных уровней рассмотрения понятия информации достаточно широко используется прагматический уровень. На данном уровне информация рассматривается с точки зрения ее полезности (ценности) для достижения потребителем информации (человеком) поставленной практической цели. Данный подход при определении полезности информации основан на расчете приращения вероятности достижения цели до и после получения получения информации [1]. Количество информации, определяющее ее ценность (полезность), находится по формуле:

где Р0, P1 – вероятность достижения цели соответственно до и после получения информации.
В качестве единицы измерения (меры) количества информации, определяющей ее ценность, может быть принят 1 бит (при основании логарифма, равном 2), т. е. это такое количество полученной информации, при котором отношение вероятностей достижения цели равно 2.
Рассмотрим три случая, когда количество информации, определяющее ее ценность, равно нулю и когда она принимает положительное и отрицательное значение.
Количество информации равно нулю при Р0 = Р1, т.е. полученная информация не увеличивает и не уменьшает вероятность достижения цели.
Значение информации является положительной величиной при P1 > P0, т. е. полученная информация уменьшает исходную неопределенность и увеличивает вероятность достижения цели.
Значение информации является отрицательной величиной при P1 < P0, т. е. полученная информация увеличивает исходную неопределенность и уменьшает вероятность достижения цели. Такую информацию называют дезинформацией.
Дальнейшее развитие данного подхода базируется на статистической теории информации и теории решений. При этом кроме вероятностныхарактеристик достижения цели после получения информации вводятся функции потерь и оценка полезности информации производится в результате минимизации функции потерь. Максимальной ценностью обладает то количество информации, которое уменьшает потери до нуля при достижении поставленной цели [1].
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Определение количества процессоров в системе
Определение количества процессоров в системе Фактически, на количество процессоров, установленных в системе, указывает маска родства системы; чтобы его определить, вам достаточно подсчитать количество ненулевых битов в маске. Вместе с тем, гораздо проще вызвать функцию
Уменьшение количества выводимых сообщений
Уменьшение количества выводимых сообщений Для того чтобы уменьшить шум, связанный с сообщениями, которые выдаются во время сборки, но в то же время видеть предупреждения и сообщения об ошибках, можно использовать такую хитрость, как перенаправление стандартного вывода
Единицы измерения CSS
Единицы измерения CSS Единицы измерения CSSВ этой таблице перечислены все единицы измерения, поддерживаемые CSS.Единица измерения === ОбозначениеВысота буквы M текущего шрифта === emВысота буквы x текущего шрифта === exПикселы === pxПункты === ptПики === pcДюймы === inМиллиметры ===
Задание и получение предельного количества транзитных узлов
Задание и получение предельного количества транзитных узлов Предельное количество транзитных узлов обычно задается параметром сокета IPV6_UNICAST_HOPS для дейтаграмм направленной передачи (см. раздел 7.8) или параметром сокета IPV6_MULTICAST_HOPS для дейтаграмм многоадресной передачи
Эффект наличия слишком большого количества дочерних процессов
Эффект наличия слишком большого количества дочерних процессов В табл. 30.1 (строка 2) указано время (1,8 с), затрачиваемое центральным процессором в случае наличия 15 дочерних процессов, обслуживающих не более 10 клиентов. Мы можем оценить эффект «общей побудки», увеличивая
Эффект наличия слишком большого количества дочерних процессов
Эффект наличия слишком большого количества дочерних процессов Мы можем проверить, возникает ли в данной версии сервера эффект «общей побудки», рассмотренный в предыдущем разделе. Как и раньше, время работы ухудшается пропорционально числу избыточных дочерних
Увеличение количества ключевых слов
Увеличение количества ключевых слов Одно или два слова при поиске используют в основном начинающие пользователи. Видавшие виды пользователи Интернета включают в запрос в среднем пять или шесть ключевых слов, чтобы уменьшить количество ненужной информации и сделать
1.3.3.5. Изменение количества рабочих столов
1.3.3.5. Изменение количества рабочих столов Щелкните правой кнопкой мыши на переключателе рабочих столов и выберите в раскрывшемся контекстном меню команду Параметры, Раскроется окно, в котором вы сможете установить количество рабочих столов и параметры их переключателя
Определения максимального количества выводимых браузером символов
Определения максимального количества выводимых браузером символов Существует еще одна интересная возможность — указание запрета вывода строк текста больше определенного количества символов. Другими словами, можно указать количество символов в строке текста, после
Единицы измерения
Единицы измерения В типографике принята своя, особая система единиц измерения, отличающаяся и от привычных нам сантиметров-миллиметров, и от зарубежных дюймов с футами. Как мы увидим при изучении программы Adobe InDesign, эти единицы измерения до сих пор используются, несмотря
11.1. Подсчет количества элементов в контейнере
11.1. Подсчет количества элементов в контейнере ПроблемаТребуется найти количество элементов в контейнере.РешениеПодсчитать количество элементов в контейнере можно при помощи функции-члена size или функции distance, определенной в заголовочном файле <algorithm>, как это
11.2.2. Определение количества повторений
11.2.2. Определение количества повторений Указав в команде uniq опцию -c, можно не только отбросить повторяющиеся строки, но и узнать, сколько раз повторяется каждая строка. В следующем примере команда uniq сообщает о том, что первая строка "May Day" встречается три раза подряд:$ uniq -с
29.4.4. Счетчик количества посещений
29.4.4. Счетчик количества посещений Создадим документ, в котором отображается счетчик количества посещений. Счетчик будет выдавать сообщение типа "you are the nth visitor to this site" ("вы являетесь n–м посетителем этого сайта"). Можно также отображать дату последнего изменения
1.2. Понятие информации. Общая характеристика процессов сбора, передачи, обработки и накопления информации
1.2. Понятие информации. Общая характеристика процессов сбора, передачи, обработки и накопления информации Вся жизнь человека так или иначе связана с накоплением и обработкой информации, которую он получает из окружающего мира, используя пять органов чувств – зрение,
3. ОПРЕДЕЛЕНИЕ СОСТАВА ЗАЩИЩАЕМОЙ ИНФОРМАЦИИ
3. ОПРЕДЕЛЕНИЕ СОСТАВА ЗАЩИЩАЕМОЙ ИНФОРМАЦИИ 3.1. Методика определения состава защищаемой информацииОпределение состава защищаемой информации — это первый шаг на пути построения системы защиты. От Того, насколько он будет точно выполнен, зависит результат