Обмен сообщениями микроядра
Обмен сообщениями микроядра
Модель обмена сообщениями — это тот фундамент, на котором стоит архитектура любой микроядерной ОС, как на трех китах: SEND — RECEIVE — REPLY. Обмен сообщениями микроядра построен на трех группах вызовов native API QNX (рис. 5.1):
1. Принять сообщение. Процесс[38], являющийся сервером некоторой услуги, выполняет вызов группы MsgReceive*()[39], фактически сообщая этим о готовности обслуживать запрос клиента, и переходит при этом в блокированное состояние со статусом RECEIVE, ожидая прихода клиентского запроса.
2. Послать сообщение. Клиентский процесс запрашивает эту услугу, посылая сообщение вызовом MsgSend*(), и переходит в блокированное состояние со статусом SEND. Переход осуществляется обычно на очень короткое время, пока сервер не примет его сообщение и не начнет обработку. Как только сервер принимает посланное сообщение, он разблокируется и меняет статус с RECEIVE на READY. Сервер начинает обработку полученного сообщения, а статус блокировки клиентского процесса меняется на REPLY.
3. Ответить на полученное сообщение. Завершив обработку полученного на предыдущем шаге сообщения, сервер выполняет вызов группы MsgReply*() для передачи запрошенного результата ожидающему клиенту. После этого вызова клиент, блокированный на вызове MsgSend*() со статусом REPLY, разблокируется (переходит в состояние READY). После выполнения MsgReply*() сервер также переходит в состояние READY. Однако чаще всего сервер снова входит в блокированное состояние на вызове MsgReceive*(), поскольку его работа организована как бесконечный цикл.
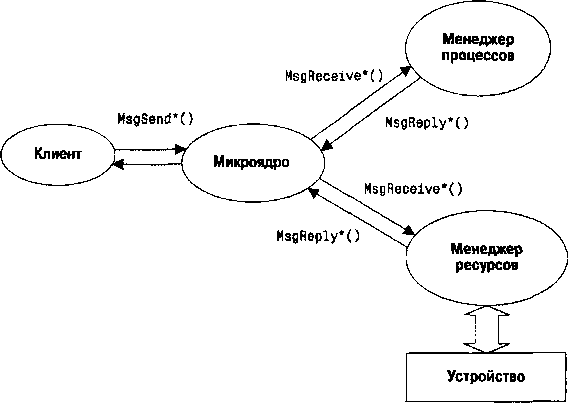
Рис. 5.1. Обмен сообщениями микроядра и менеджер ресурсов
Уже из этого поверхностного описания понятно, что передача сообщений микроядра — это не только средство взаимодействия процессов с обменом данными, но и крайне гибкая система синхронизации всех участников взаимодействия.
Могут возникнуть вопросы: Это один из низкоуровневых механизмов (существуют ли другие нативные механизмы?), на которых базируется ОС QNX? Какое это может иметь отношение к взаимодействиям на уровне POSIX API? Самое прямое! Все традиционные вызовы POSIX (open(), read(), … и все другие) реализованы в ОС QNX как обмен сообщениями, который только «камуфлируется» под стандарты техникой использования менеджеров ресурсов, о которых разговор еще впереди.
Технология обмена сообщениями микроядра хорошо описана [1] и требует для своего понимания и освоения тщательного изучения. В этой же главе, посвященной совершенно другим предметам, мы не будем детально описывать эту технологию.
Остановимся только на одном обстоятельстве: адресат получателя, которому направляется каждое сообщение, определяется при начальном установлении идентификатора соединения (coid — connect ID) вызовом:
#include <sys/neutrino.h>
int ConnectAttach(int nd, pid_t Did, int chid,
unsigned index, int flags);
Адрес назначения (сервера) в этом вызове определяется триадой {ND/PID/CHID}, где:
nd — идентификатор сетевого узла. Мы не станем углубляться в идентификацию сетевых узлов сети QNET. Возьмем на заметку лишь тот факт, что обмен сообщениями с одинаковой легкостью осуществляется как с процессом на локальном узле (nd = 0), так и на любом другом сетевом узле.
pid — PID процесса-сервера, с которым производится соединение.
chid — идентификатор канала, который открыл процесс с указанным PID, выполнив предварительно ChannelCreate(), и к которому устанавливается соединение вызовом ConnectAttach().
Выше мы неоднократно отмечали, что с процессом как с пассивной субстанцией, вообще говоря, невозможно обмениваться сообщениями. Хотя в адресной триаде обмена фигурирует именно PID процесса! Это обстоятельство не меняет положения вещей: именно адресная компонента CHID и определяет тот поток (часто это может быть главный поток приложения), с которым будет осуществляться обмен сообщениями, a PID определяет то адресное пространство процесса, в которое направляется сообщение, адресованное CHID.
Детальнее это выглядит так: в коде сервера именно тот поток, который выполнит MsgReceive*(chid, ...), и будет заблокирован в ожидании запроса от клиента MsgSend*(). Аналогично и в коде клиента вся последовательность выполнения блокировок, обозначенная выше, будет относиться именно к потоку, выполняющему последовательные операции:
coid = ConnectAttach(... , chid, ...);
MsgSend*(coid, ...);
Содержимое двух предыдущих абзацев ни одной буквой не противоречит и не отменяет положения традиционного изложения [1] технологии обмена сообщениями микроядра. Тогда зачем же мы даем именно такую формулировку? Для того чтобы акцентировать внимание на том, что все блокированные состояния и их освобождение имеют смысл относительно потоков (и только потоков!), которые выполняют последовательность операций MsgSend*() — MsgReceive*() — MsgReply*() (даже если это единственный поток — главный поток приложения, и тогда мы говорим о блокировании процессов). Проиллюстрируем сказанное следующим приложением (файл n1.cc):
Обмен сообщениями и взаимные блокировки
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <inttypes.h>
#include <errno.h>
#include <iostream.h>
#include <pthread.h>
#include <signal.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
static const int TEMP = 500; // темп выполнения приложения
static int numclient = 1; // число потоков клиентов
// многопотоковая версия вывода диагностики в поток:
iostream& operator <<(iostream& с, char* s) {
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&mutex);
c << s << flush;
pthread_mutex_unlock(&mutex);
return c;
}
static uint64_t tb; // временная отметка начала приложения
// временная отметка точки вызова:
inline uint64_t mark(void) {
// частота процессора:
const static uint64_t cps =
SYSPAGE_ENTRY(qtime)->cycles_per_sec;
return (ClockCycles() - tb) * 1000 / cps;
}
const int MSGLEN = 80;
// потоковая функция сервера:
void* server(void* chid) {
int rcvid;
char message[MSGLEN];
while (true) {
rcvid = MsgReceive((int)chid, message, MSGLEN, NULL);
sprintf(message + strlen(message), "[%07llu] ... ", mark());
delay(TEMP); // имитация обслуживания
sprintf(message + strlen(message), [%07llu]->", mark());
MsgReply(rcvid, EOK, message, strlen(message) + 1);
}
return NULL;
}
// потоковая функция клиента:
void* client(void* data) {
while (true) {
char message[MSGLEN];
sprintf(message, "%d: [%07llu]->", pthread_self(), mark());
MsgSend((int)data, message, strlen(message) + 1, message, MSGLEN);
sprintf(message + strlen(message), "[%07llu]", mark());
cout << message << endl;
static unsigned int seed = 0;
delay(numclient*(((long)rand_r(&seed ) * TEMP / RAND_MAX) + TEMP));
// имитация вычислений...
}
return NULL;
}
int main(int argc, char** argv) {
// 1-й параметр - число потоков клиентов:
if (argc > 1 && atoi(argv[1]) > 0)
numclient = atoi(argv[1]);
tb = ClockCycles();
int chid = ChannelCreate(0);
if (pthread_create(NULL, NULL, server, (void*)chid) != EOK)
perror("server create"), exit(EXIT_FAILURE);
for (int i = 0; i < numclient; i++)
if (pthread_create(NULL, NULL, client,
(void*)ConnectAttach(0, 0, chid, _NTO_SIDE_CHANNEL, 0)) != EOK)
perror("client create"), exit(EXIT_FAILURE);
sigpause(SIGINT);
return EXIT_SUCCESS;
}
Все происходит в рамках единого процесса:
• Создается единый поток сервера, ожидающий сообщений от клиентов и отвечающий на них.
• Создается N потоков клиентов (задается параметром командной строки запуска приложения), которые будут обращаться к серверу.
• К одному каналу сервера устанавливается N соединений от клиентов.
• Канал прослушивания для сервера и идентификаторы соединений для клиентов сознательно создаются в главном потоке (т.e. вне потоков, которые их будут использовать); их значения поступают в потоки (сервера и клиентов) как параметры потоковых функций (трюк с подменой целочисленных значений на указатели мы рассматривали ранее).
• Сообщение продвигается от клиента к серверу и обратно к клиенту; в ходе пересылки объем сообщения нарастает: оно образуется конкатенацией полей, добавляемых последовательно клиентом, сервером и снова клиентом.
• В результате полного цикла обмена сообщением в теле самого сообщения формируется текст, содержащий 5 последовательных полей — идентификатор потока клиента (обращающегося с сообщением) и 4 абсолютные временные метки (в миллисекундах): передачи сообщения клиентом, приема сообщения сервером (начало обработки), ответа на сообщение сервером (конец обработки), приема ответа клиентом.
Запустим полученное приложение, например, так:
# n1 5
И прежде чем обсуждать результаты его работы, понаблюдаем состояния (блокировки) его потоков командой pidin (с другого терминала, естественно). Вот несколько «снимков» состояний, здесь можно наблюдать весь спектр блокированных состояний, о которых говорилось выше:
5546027 1 ./n1 10r SIGSUSPEND
5546027 2 ./n1 10r NANOSLEEP
5546027 3 ./n1 10r NANOSLEEP
5546027 4 ./n1 10r SEND 5546027
5546027 5 ./n1 10r REPLY 5546027
5546027 6 ./n1 10r NANOSLEEP
5546027 7 ./n1 10r NANOSLEEP
5730347 1 ./n1 10r SIGSUSPEND
5730347 2 ./n1 10r RECEIVE 1
5730347 3 ./n1 10r NANOSLEEP
5730347 4 ./n1 10r NANOSLEEP
5730347 5 ./n1 10r NANOSLEEP
5730347 6 ./n1 10r NANOSLEEP
5730347 7 ./n1 10r NANOSLEEP
А теперь рассмотрим результаты выполнения (на меньшем числе потоков клиентов, которое легче анализировать):
# n1 3
3: [0000000]->[0000000] ... [0000501]->[0000501]
4: [0000000]->[0000501] ... [0001003]->[0001003]
5: [0000000]->[0001003] ... [0001505]->[0001505]
3: [0002003]->[0002003] ... [0002504]->[0002505]
5: [0003462]->[0003462] ... [0003964]->[0003964]
4: [0003485]->[0003964] ... [0004466]->[0004466]
3: [0005017]->[0005017] ... [0005518]->[0005518]
5: [0005624]->[0005624] ... [0006126]->[0006126]
4: [0006741]->[0006741] ... [0007243]->[0007243]
...
Видно, как 3 клиента отправляют сообщения одновременно ([0000000]), поток сервера (TID = 2) немедленно получает сообщение ([0000000], 1-я строка), отправленное клиентом с TID = 3, два других сообщения (от клиентов с TID = 4 и 5) помещаются системой в очередь обслуживания (строки 2 и 3). После завершения обслуживания запроса от TID = 3 и ответа ([0000501]) поток сервера получает (извлекается из очереди ранее отправленное сообщение) сообщение от TID = 4 и так далее.
Еще содержательнее для интерпретации становится картина для большего числа потоков клиентов (здесь очередь ожидающих запросов становится гораздо длиннее, а ее поведение трудно предсказуемым - почти каждый запрос ожидает обслуживания), но эти результаты требуют намного более тщательного разбора для их осмысления:
# n1 10
3: [0000000]->[0000000] ... [0000501]->[0000501]
4: [0000000]->[0000501] ... [0001003]->[0001003]
5: [0000000]->[0001003] ... [0001505]->[0001505]
6: [0000000]->[0001505] ... [0002007]->[0002007]
7: [0000000]->[0002007] ... [0002508]->[0002508]
8: [0000000]->[0002508] ... [0003010]->[0003010]
9: [0000000]->[0003010] ... [0003512]->[0003512]
10: [0000000]->[0003512] ... [0004014]->[0004014]
11: [0000000]->[0004014] ... [0004516]->[0004516]
12: [0000000]->[0004516] ... [0005017]->[0005018]
3: [0005501]->[0005501] ... [0006003]->[0006003]
5: [0008024]->[0008024] ... [0008526]->[0008526]
7: [0008038]->[0008526] ... [0009028]->[0009028]
4: [0009273]->[0009273] ... [0009775]->[0009775]
6: [0010377]->[0010377] ... [0010878]->[0010878]
8: [0010590]->[0010878] ... [0011380]->[0011380]
9: [0010952]->[0011380] ... [0011882]->[0011882]
12: [0011297]->[0011882] ... [0012384]->[0012384]
11: [0011356]->[0012384] ... [0012886]->[0012886]
10: [0012024]->[0012886] ... [0013387]->[0013388]
3: [0012874]->[0013388] ... [0013889]->[0013889]
7: [0014888]->[0014888] ... [0015390]->[0015390]
4: [0016254]->[0016254] ... [0016756]->[0016756]
5: [0017646]->[0017646] ... [0018148]->[0018148]
6: [0019088]->[0019088] ... [0019590]->[0019590]
11: [0020206]->[0020206] ... [0020708]->[0020708]
8: [0020320]->[0020708] ... [0021210]->[0021210]
10: [0021078]->[0021210] ... [0021712]->[0021712]
12: [0021384]->[0021712] ... [0022213]->[0022213]
7: [0021630]->[0022213] ... [0022715]->[0022715]
9: [0021811]->[0022715] ... [0023217]->[0023217]
3: [0022009]->[0023217] ... [0023719]->[0023719]
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Обмен сообщениями
Обмен сообщениями В данной главе вы ознакомитесь с наиболее яркой и фундаментальной особенностью QNX/Neutrino — принципом обмена сообщениями. Вы изучите, что такое обмен сообщениями, как его применять для общения потоков между собой, и как обмениваться сообщениями по сети.
Глава 2 Обмен сообщениями
Глава 2 Обмен сообщениями Введение в обмен сообщениями В данной главе мы рассмотрим наиболее характерную отличительную особенность QNX/Neutrino — механизм обмена сообщениями. Обмен сообщениями в QNX/Neutrino — ключевой механизм, глубоко интегрированный с микроядерной
Введение в обмен сообщениями
Введение в обмен сообщениями В данной главе мы рассмотрим наиболее характерную отличительную особенность QNX/Neutrino — механизм обмена сообщениями. Обмен сообщениями в QNX/Neutrino — ключевой механизм, глубоко интегрированный с микроядерной архитектурой этой операционной
Микроядро и обмен сообщениями
Микроядро и обмен сообщениями Одним из основных преимуществ QNX/Neutrino является то, что данная операционная система является масштабируемой. Под «масштабируемостью» здесь подразумевается, что данная система может быть адаптирована к работе как в крошечных встраиваемых
Обмен сообщениями и модель «клиент/сервер»
Обмен сообщениями и модель «клиент/сервер» Представьте, что приложение читает данные из файловой системы. На языке QNX это значит, что данное приложение — это клиент, запрашивающий данные у сервера.Модель «клиент/сервер» позволяет говорить о нескольких рабочих
Распределенный обмен сообщениями
Распределенный обмен сообщениями Предположим, что мы пожелали изменить приведенный выше пример, чтобы можно было «поговорить» с другим узлом сети. Вы, наверное, думаете, что для этого придется вызывать специальные функции, чтобы «попасть в сеть». Вот сетевой вариант
Обмен сообщениями и многопоточность
Обмен сообщениями и многопоточность При том, что модель «клиент/сервер» проста для понимания и очень широко используется, существуют две вариации на данную тему. Первая — многопоточная реализация (об этом речь в данной главе), вторая — так называемая модель
Обмен сообщениями в сети
Обмен сообщениями в сети Прозрачный обмен сообщениями в сети не поддерживается в версии QNX/Neutrino 2.00, но это намечено к реализации в более поздних версиях данной ОС. (Поддержка этого механизма реализована в QNX/Neutrino, начиная с версии 2.11, и присутствует в QNX Realtime Platform, начиная
16.5 Идентификация получателя и обмен сообщениями
16.5 Идентификация получателя и обмен сообщениями В Интернете получатель почтового сообщения идентифицируется по имени с использованием следующего общего формата:локальная_часть@имя_доменаЭтот формат очень гибок. Многие годы в Интернете предпочитали формат с
16.18 Обмен сообщениями через X.400
16.18 Обмен сообщениями через X.400 Всемирный телекоммуникационный союз (ITU) несет ответственность за поддержку международных коммуникаций и выпуск рекомендаций для обеспечения телеграфной, телефонной и факсимильной связи между странами.Сектор стандартов этой организации
Обмен мгновенными сообщениями
Обмен мгновенными сообщениями Со временем, когда ваш журнал обрастет могучей кучкой друзей, читателей и почитателей, у вас наверняка возникнет желание хотя бы изредка переброситься с ними парой слов не через посредство самого блога, а как-то более конфиденциально.В
Обмен быстрыми сообщениями в сети MSN
Обмен быстрыми сообщениями в сети MSN Протокол MSNP (от англ. Mobile Status Notification Protocol – протокол для мобильного оповещения) используется в программах MSN Messenger, Windows Messenger, которые уже несколько устарели, но продолжают эксплуатироваться, а также в программе Windows Live Messenger (рис. 5.7),
9.4. ICQ: мгновенный обмен сообщениями
9.4. ICQ: мгновенный обмен сообщениями ICQ — самый популярный сервис мгновенного обмена сообщениями на наших просторах. Это не отечественный сервис, но у нас он прижился лучше, чем все остальные сервисы подобного рода. Практически у каждого интернет-пользователя есть свой
Обмен мгновенными сообщениями
Обмен мгновенными сообщениями Теперь перейдем к краткому обзору других служб Интернета. Среди них одной из наиболее популярных сегодня является обмен мгновенными сообщениями.Эта служба позволяет людям общаться между собой с помощью коротких сообщений еще более