Соображения производительности
Соображения производительности
Интересны не только затраты на порождение нового процесса (мы еще будем к ним неоднократно возвращаться), но и то, насколько «эффективно» сосуществуют параллельные процессы в ОС, насколько быстро происходит переключение контекста с одного процесса на другой. Для самой грубой оценки этих затрат создадим простейшее приложение (файл p5.cc):
Затраты на взаимное переключение процессов
#include <stdlib.h>
#include <inttypes.h>
#include <iostream.h>
#include <unistd.h>
#include <sched.h>
#include <sys/neutrino.h>
int main(int argc, char* argv[]) {
unsigned long N = 1000;
if (argc > 1 && atoi(argv[1]) > 0)
N = atoi(argv[1]);
pid_t pid = fork();
if (pid == -1)
cout << "fork error" << endl, exit(EXIT_FAILURE);
uint64_t t = ClockCycles();
for (unsigned long i = 0; i < N; i++) sched_yield();
t = ClockCycles() - t;
delay(200);
cout << pid << " : cycles - " << t << "; on sched - " << (t/N) / 2 << endl;
exit(EXIT_SUCCESS);
}
Два одновременно выполняющихся процесса настолько симметричны и идентичны, что они даже не анализируют PID после выполнения fork(), они только в максимальном темпе «перепасовывают» друг другу активность, как волейболисты делают это с мячом (рис. 2.2).
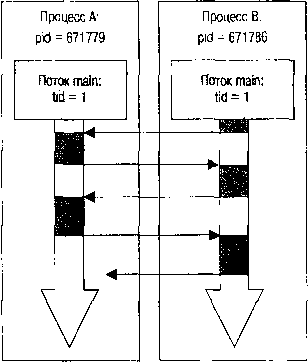
Рис. 2.2. Симметричное взаимодействие потоков
Рисунок 2.2 иллюстрирует взаимодействие двух идентичных процессов: вся их «работа» состоит лишь в том, чтобы как можно быстрее передать управление партнеру. Такую схему, когда два и более как можно более идентичных потоков или процессов в максимально высоком темпе (на порядок превосходящем последовательность «естественной» RR-диспетчеризации) обмениваются активностью, мы будем неоднократно использовать в дальнейшем для различных механизмов, называя ее для простоты «симметричной схемой».
Примечание
Чтобы максимально упростить код приложения, при его написании мы не трогали события «естественной» диспетчеризации, имеющие место при RR-диспетчеризации каждые 4 системных тика (по умолчанию это ~4 миллисекунды). Как сейчас покажут результаты, события принудительной диспетчеризации происходят с периодичностью порядка 1 микросекунды, т.e. в 4000 раз чаще, и возмущения, возможно вносимые RR-диспетчеризацией, можно считать не настолько существенными.
Вот результаты выполнения этой программы:
# nice -n-19 p5 1000000
1069102 : cycles - 1234175656; on sched — 617
0 : cycles - 1234176052; on sched - 617
# nice -n-19 p5 100000
1003566 : cycles - 123439225; on sched — 617
0 : cycles - 123440347; on sched - 617
# nice -n-19 p5 10000
1019950 : cycles - 12339084; on sched — 616
0 : cycles - 12341520; on sched - 617
# nice -n-19 p5 1000
1036334 : cycles - 1243117; on sched — 621
0 : cycles - 1245123; on sched - 622
# nice -n-19 p5 100
1052718 : cycles - 130740; on sched — 653
0 : cycles - 132615; on sched - 663
Видна на удивление устойчивая оценка, практически не зависящая от общего числа актов диспетчеризации, изменяющегося на 4 порядка.
Отбросив мелкие добавки, привносимые инкрементом и проверкой счетчика цикла, можно считать, что передача управления от процесса к процессу требует порядка 600 циклов процессора (это порядка 1,2 микросекунды на компьютере 533 МГц, на котором выполнялся этот тест).
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
1.4.5. Заключительные соображения по поводу «GNU Coding Standards»
1.4.5. Заключительные соображения по поводу «GNU Coding Standards» GNU Coding Standards является стоящим для прочтения документом, если вы хотите разрабатывать новое программное обеспечение GNU, обмениваться существующими программами GNU или просто научиться программировать лучше. Принципы
Дополнительные соображения по оптимизации
Дополнительные соображения по оптимизации Одним из возможных выходов из сложившейся ситуации будет использование характерных для IE CSS-хаков, чтобы только для него подключить фоновые изображения. В итоге вышеприведенный пример будет выглядеть примерно так:ul {list-style: none;}ul
1. Общие соображения об анонимности в Интернет
1. Общие соображения об анонимности в Интернет Человек написал и отправил письмо по электронной почте, посетил какой-то сайт, оставил своё сообщение на форуме и т. д. Любое из указанных действий позволяет найти этого человека и узнать кто он такой. А при желании и привлечь
Вопросы производительности
Вопросы производительности При выборе оборудования для установки Asterisk главным соображением является то, насколько мощной должна быть полученная система. Это непростой вопрос, поскольку большую роль в данном случаеиграет то, как будет использоваться система. Такого
10.15 Барьеры для производительности
10.15 Барьеры для производительности TCP доказал свою гибкость, работая в сетях со скоростью обмена в сотни или миллионы бит за секунду. Этот протокол позволил достичь хороших результатов в современных локальных сетях с топологиями Ethernet, Token-Ring и Fiber Distributed Data Interface (FDDI), а
13.12 Замечания о производительности
13.12 Замечания о производительности Telnet не обеспечивает хорошей производительности. При эмуляции терминала ASCII (например, VT100) telnet очень неэффективен. Посланные клиентом сегменты часто содержат только один или несколько символов. Каждый символ нужно вернуть назад для
14.8 Замечания о производительности
14.8 Замечания о производительности На эффективность операций пересылки файлов влияют следующие факторы:? Файловая система хоста и производительность его дисков? Объем обработки по переформатированию данных? Используемая служба TCPКраткий отчет о пропускной
§ 160. Два соображения
§ 160. Два соображения 3 июня 2009— Хороший логотип должен быть таким, чтобы любой человек мог его по памяти от руки изобразить.— Это хорошо, если реклама не сразу понятна. Человек потратит время на понимание смысла и лучше запомнит такую рекламу.Из-за этих двух заблуждений
Соображения для преподавателей
Соображения для преподавателей Было несколько руководящих принципов, которых я старался придерживаться. Я думаю, они делают процесс обучения гораздо более лёгким – ведь учиться программировать и так довольно тяжело. Если вы преподаёте или наставляете кого-то на путь
Повышение производительности
Повышение производительности Окно сведений о производительности (см. рис. 8.3) не только предоставляет информацию, но и позволяет несколько повысить общую производительность системы. Для этого в левой части окна есть следующие ссылки.• Управление автозагрузкой программ.
Соображения по поводу эффективности
Соображения по поводу эффективности Если бы это было все, что можно сказать о связных списках, то глава оказалась бы очень короткой. До сих пор была представлена только реализация класса, инкапсулирующего односвязный список. Но перед написанием класса связного списка
14.8. Соображения эффективности A
14.8. Соображения эффективности A В общем случае объект класса эффективнее передавать функции по указателю или по ссылке, нежели по значению. Например, если дана функция с сигнатурой:bool sufficient_funds( Account acct, double );то при каждом ее вызове требуется выполнить почленную
Отборочные соображения
Отборочные соображения Тайм-аут, в течении которого я отвлёкся от проблем противостояния дистрибутивов, имена которых вынесены в заглавие цикла, подошёл к концу. И пора выполнять своё обещание – подвести окончательные (на сегодняшний день) итоги тому, что было сказано на