4.1. Инкапсуляция и оптимальный размер модуля
4.1. Инкапсуляция и оптимальный размер модуля
Первым и наиболее важным качеством модульного кода является инкапсуляция. Правильно инкапсулированные модули не открывают свое внутренне устройство друг другу. Они не обращаются к центральной части реализации друг друга, кроме того, они не используют глобальные данные беспорядочно. Они осуществляют связь друг с другом посредством программных интерфейсов приложений (API) — компактных, четких наборов вызовов процедур и структур данных. Именно об этом гласит правило модульности.
API-интерфейсам между модулями отведена двойная роль. На уровне реализации они функционируют как заслонка между модулями, которая предотвращает воздействие внутренних данных модулей на соседние модули. На уровне проектирования именно API-интерфейсы (а не описание структур данных между ними) действительно определяют структуру программ.
Хороший способ проверить правильность проектирования API-интерфейса — определить, будет ли ясен смысл, если попытаться описать API обычным человеческим языком (без демонстрации фрагментов исходного кода)? Весьма целесообразно выработать привычку писать неформальные описания для API-интерфейсов до их кодирования. Более того, некоторые из наиболее способных разработчиков начинают с определения интерфейсов и написания кратких комментариев для них, а затем пишут код, поскольку процесс написания комментариев разъясняет задачи, возлагаемые на код. Подобные описания помогают организовать мышление разработчика, а также создают полезные комментарии для модулей, и в конечном итоге их можно включить в справочный документ для будущих читателей кода.
Чем дальше проводится декомпозиция модулей, тем меньше становятся блоки и более важными определения API-интерфейсов, Сокращается глобальная сложность и, как следствие, уязвимость относительно ошибок. С 70-х годов прошлого века общепринятым правилом (описанном в статьях, подобных [61]) стало проектирование программных систем в виде иерархий вложенных модулей, с сохранением минимального размера модулей на каждом уровне.
Возможно, однако, что подобное разбиение на модули будет слишком строгим и приведет к появлению очень маленьких модулей, Доказано [33], что при построении диаграммы плотности дефектов относительно размера модуля, кривая становится U-образной, а ее лучи направлены вверх (см. рис. 4.1). Очень большие и очень малые модули обычно служат причиной возникновения гораздо большего количества ошибок, чем модули среднего размера. Другим способом рассмотрения тех же данных является построение диаграммы количества строк кода в модуле относительно общего количества ошибок. Кривая в таком случае подобна логарифмической кривой до зоны "наилучшего восприятия", где она сглаживается (соответственно с минимумом кривой плотности дефектов), и после которой она направляется вверх (как квадрат числа, соответствующего количеству строк кода, т.е. наблюдается то, что, согласно закону Брукса28, можно интуитивно ожидать для всей кривой).
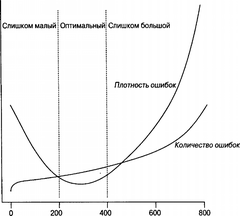
Размер модуля (число логических строк)
Рис. 4.1. Качественная диаграмма количества и плотности дефектов относительно размера модуля
Этот неожиданный рост количества ошибок при малых размерах модулей устойчиво наблюдается в широком диапазоне систем, реализованных на различных языках программирования. Хаттон (Hatton) предложил модель, связывающую данную нелинейную зависимость с объемом краткосрочной человеческой памяти29. Другая интерпретация данной нелинейной зависимости состоит в том, что при малых размерах элемента модуля возрастающая сложность интерфейсов становится доминирующим фактором. Трудно читать код, поскольку необходимо понять все еще до того, как станет возможным понять что-либо. В главе 7 рассматриваются более сложные формы разделения программ. В них также сложность интерфейсных протоколов начинает доминировать на фоне общей сложности системы по мере уменьшения размеров процессов
В нематематических понятиях эмпирические результаты Хаттона предполагают точку наилучшего восприятия между 200 и 400 логических строк кода, где сведена к минимуму возможная плотность дефектов, а все остальные факторы (такие как профессионализм программиста) равны. Размер не зависит от используемого языка программирования. Это замечание весьма усиливает приводимый в данной книге совет о программировании с использованием наиболее мощных из доступных языков и инструментов. Не следует однако принимать данные числа слишком буквально. Методы подсчета строк кода в значительной степени различаются в зависимости от того, как аналитик определяет логическую строку, а также от других условий (например, от того, отбрасываются ли комментарии). Сам Хаттон в качестве приближенного подсчета советует использовать двукратное преобразование между логическими и физическими строками, рекомендуя оптимальный диапазон в 400-800 физических строк кода.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Оптимальный порядок
Оптимальный порядок Используя браузерные префиксы, важно не забывать о порядке, в котором перечисляются свойства. Можно заметить, что в предыдущем примере сначала написаны префиксные свойства, за которыми следует беспрефиксное свойство.Зачем ставить подлинное
Инкапсуляция IP
Инкапсуляция IP При работе в локальной сети на базе технологии CSMA/CD возможны два варианта инкапсуляции датаграмм IP в кадры уровней LLC и MAC.Первый заключается в использовании кадров Ethernet 2.0. В этом случае поле данных (1500 октетов) полностью принадлежит IP-датаграмме, a SAP
Каков оптимальный размер текстов на сайте
Каков оптимальный размер текстов на сайте Теперь давайте разберемся, какой объем в среднем должен иметь ваш текст. Это очень важно, так как многие люди не понимают, какое количество слов и символов им стоит использовать в тексте, для того чтобы он получился емким и
Инкапсуляция и С++
Инкапсуляция и С++ Предположим, что вам удалось преодолеть проблемы с транслятором и компоновщиком, описанные в предыдущем разделе. Очередное препятствие при построении двоичных компонентов на C++ появится, когда вы будете проводить инкапсуляцию (encapsulation), то есть
4.1. Инкапсуляция и оптимальный размер модуля
4.1. Инкапсуляция и оптимальный размер модуля Первым и наиболее важным качеством модульного кода является инкапсуляция. Правильно инкапсулированные модули не открывают свое внутренне устройство друг другу. Они не обращаются к центральной части реализации друг друга,
Инкапсуляция
Инкапсуляция Первым принципом ООП является инкапсуляция. По сути, она означает возможность скрыть средствами языка несущественные детали реализации от пользователя объекта. Предположим, например, что мы используем класс DatabaseReader, который имеет два метода Open() и Close().//
Размер страницы и размер кэша по умолчанию
Размер страницы и размер кэша по умолчанию При восстановлении вы можете изменить размер страницы, включив в команду переключатель -р[age_size], за которым следует целое число, задающее размер в байтах. Допустимые размеры страниц см. в табл. 38.2.В этом примере gbak восстанавливает
Инкапсуляция
Инкапсуляция Инкапсуляция не определяет вершину мира. Нет ничего такого, что могло бы возвысить инкапсуляцию. Она полезна только потому, что влияет на другие аспекты нашей программы, о которых мы заботимся. В частности, она обеспечивает гибкость программы и ее
Минимальность и инкапсуляция
Минимальность и инкапсуляция В "Эффективном использовании C++" (Effective C++), я приводил доводы в пользу интерфейсов класса, которые являются полными и минимальный [10]. Такие интерфейсы позволяют клиентам класса делать что-либо, что они могли бы предположительно хотеть делать,
Человек оптимальный
Человек оптимальный Автор: Владимир ГуриевНекоторые темы, популярные каких-то сорок лет назад, сегодня кажутся настолько маргинальными, что всерьез почти не обсуждаются. Тогда же — если судить по тону статей в популярных журналах — они казались актуальными и даже
Каков оптимальный уровень мониторинга?
Каков оптимальный уровень мониторинга? Какой уровень трассировки следует включать? Ответ вырабатывается в результате компромисса, с учетом следующих факторов: уровня доверия к корректности ПО, насколько критичны потери эффективности, насколько серьезны последствия не
Размер головного мозга и размер социального окружения
Размер головного мозга и размер социального окружения Дискуссии по поводу взаимосвязи между размером головного мозга какого-либо организма и размером группы, к которой этот организм принадлежит, ведутся нейробиологами уже давно. При этом взаимосвязь с социальной