Эксперимент с Quality Bots
Эксперимент с Quality Bots
Как изменится тестирование, если мы забудем о наших методах и инструментах, а возьмем на вооружение инфраструктуру поисковых движков? Почему бы и нет, ведь там есть бесплатное процессорное время, свободное пространство и дорогая система вычисления, работающая над алгоритмами! Давайте поговорим о ботах, а конкретнее — о Quality Bots.
Завершив множество проектов по тестированию в Google и поговорив со многими командами, мы осознали, что блестящие умы наших инженеров часто растрачиваются на ручное построение и выполнение регрессионных тестов. Поддерживать автоматизированные тестовые сценарии и вручную проводить регрессионное тестирование — дорогое удовольствие. К тому же медленное. Добавляет масла в огонь то, что мы проверяем ожидаемое поведение, — а как же неожиданное?
Регрессионные тесты обычно проходят без ошибок в более чем 95% случаев. Скорее всего, так происходит потому, что практика разработки в Google заточена на качество. Но, что важно, эта рутинная работа притупляет способности инженеров, которых мы нанимали вообще-то за любознательность и изобретательность. Мы хотим освободить наших ребят для более сложного, исследовательского тестирования, для которого, собственно, мы их и брали в команду.
Google Search постоянно сканирует веб-пространство: запоминает, что видит, упорядочивает и ранжирует полученные данные в огромных индексах, руководствуясь статической и динамической релевантностью (качеством информации), а потом выдает информацию по запросу на странице результатов поиска. Если хорошенько подумать, базовая архитектура системы поиска может быть отличным примером автоматизированной системы оценки качества. Выглядит как идеальный движок для тестирования. Мы не стали два раза вставать и построили себе версию этой системы.
1. Обход. Боты работают в вебе[48] прямо сейчас. Тысячи виртуальных машин, вооруженные скриптами WebDriver, открывают в основных браузерах популярные URL-адреса. Перепрыгивая от одного URL-адреса к другому, словно обезьянки с лианы на лиану, они анализируют структуру веб-страниц, на которые приземляются. Они строят карту, которая показывает, какие элементы HTML отображаются, где и как.
2. Индексирование. Боты передают сырые данные серверам индексирования, где информация упорядочивается по типу браузера и времени обхода. Формируется статистика о различиях между обходами, например количество обойденных страниц.
3. Ранжирование. Когда инженер хочет посмотреть результаты для конкретной страницы по разным обходам или результаты всех страниц для одного браузера, система ранжирования вычисляет оценку качества. Проще говоря, система оценивает сходство страниц в процентах: 100% означает, что страницы идентичны. Соответственно, чем меньше процент сходства, тем больше различий.
4. Результаты. На информационной панели можно посмотреть сводку результатов (рис. 3.27). Подробные результаты строятся в виде простой таблицы оценок для каждой страницы с указанием сходства в процентах (рис. 3.28 и 3.29). Для каждого результата инженер может копнуть глубже и получить информацию о визуальных различиях. Они показаны с помощью наложения результатов разных проходов с указанием XPath-путей[49] элементов и их позиций (рис. 3.30). Инструмент показывает средние минимальные и максимальные исторические показатели этого URL-адреса и другую подобную информацию.

Рис. 3.27. Сводка информации для разных сборок Chrome

Рис. 3.28. Типичная таблица с подробной информацией от ботов
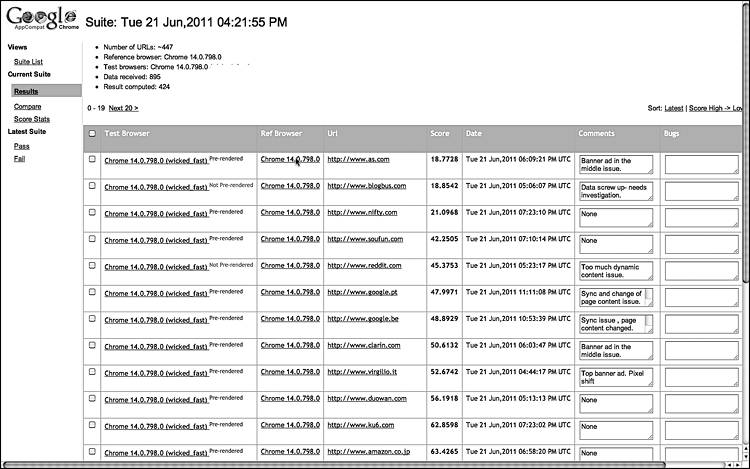
Рис. 3.29. Таблица информации от ботов, отсортированная для выявления наибольших различий

Рис. 3.30. Анализ визуальных различий для идентичных страниц
Первый же официальный запуск проекта нашел различие между двумя канареечными сборками Chrome. Боты провели проверку автоматически. Тестировщик оценил результаты и заметил, что этот URL-адрес потерял несколько процентов сходства. Тестировщик быстро сообщил о проблеме, ссылаясь на подробную картинку (рис. 3.31) с выделенной частью страницы с различиями. Раз боты могли протестировать все версии Chrome,[50] инженер мог быстро справляться с новыми регрессионными багами. Каждая сборка содержала всего несколько изменений, и заливку с проблемным кодом оперативно изолировали. Оказалось, что коммит[51] в репозиторий WebKit (ошибка 56859: reduce float iteration in logicalLeft/RightOffsetForLine) вызвал регрессионный баг,[52] из-за которого средний элемент div на этой странице стал отображаться ниже границы страницы. Тестировшик завел баг 77261: Макет страницы ezinearticles.com неправильно отображается в Chrome 12.0.712.0.
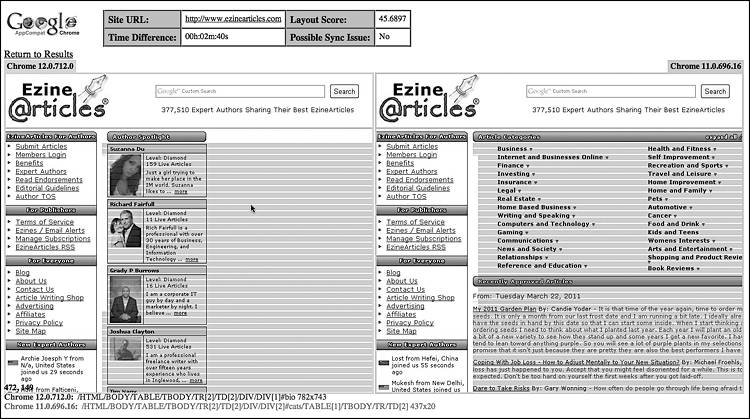
Рис. 3.31. Первый баг, обнаруженный при первом запуске ботов
Как мы прогнозировали (и надеялись), данные от ботов оказались очень похожи на данные, получаемые от их одушевленных аналогов, и во многом даже лучше. Большинство веб-страниц оказывались идентичными в разных версиях браузеров, и даже если находилось различие, инженер быстро просматривал его и понимал, есть ли что-то серьезное.
Машины теперь могли автоматически подтвердить отсутствие регрессионных багов. Это маленький шаг для машины, но огромный для всего мира тестировщиков — им больше не нужно пробираться через тернии не самых интересных страниц. Тесты теперь можно прогонять за минуты, а не за несколько дней, как раньше. Их можно проводить ежедневно, а не еженедельно. У тестировщиков наконец освободились руки и время и стало возможным заняться багами посложнее.
Если оставить версию браузера неизменной, а менять при этом только данные одного сайта, мы получим средство для тестирования сайтов, а не только браузера. Такую же штуку можно провернуть с анализом одного URL-адреса по всем браузерам и всем сериям тестов. То есть у веб-разработчика появилась возможность просмотреть все изменения, происходящие с его сайтом: он создает новую сборку, дает ботам ее обойти и получает таблицу результатов, где показаны все изменения. Быстро, безо всякого ручного тестирования, веб-разработчик определяет, какие изменения из обнаруженных не заслуживают внимания, а какие похожи на регрессионный баг и достойны занесения в багтрекинговую систему, причем сразу с информацией о браузерах, версии приложения и конкретных элементах HTML, где он водится.
А как насчет веб-сайтов, управляемых данными? Возьмем, например, сайты YouTube и CNN — их контент огромен и изменяется со временем. Не запутаются ли боты? Они справятся, если будут предупреждены о нормальных колебаниях данных этого сайта. Например, если в нескольких последовательных сериях изменился только текст статьи и картинки, то боты посчитают изменения уместными для данного сайта. Если показатели выйдут за рамки (допустим, при нарушении IFRAME или при переходе сайта на другой макет), боты могут подать сигнал тревоги и сообщить об этом веб-разработчику, чтобы он определил, нормально ли новое состояние или пора заводить соответствующий баг. Пример небольшого шума можно увидеть на рис. 3.32: на сайте CNET есть реклама, которая во время проверки

Рис. 3.32. Анализ визуальных различий для страниц с шумовыми различиями
появилась справа, а не слева. Такой шум считается небольшим и будет либо проигнорирован ботом, либо помечен как несущественный человеком, который моментально заметит, что это всего лишь реклама.
А что происходит дальше со всеми этими сигналами? Должен ли тестировщик или разработчик просматривать их все? На самом деле нет, мы уже ведем эксперименты по прямой передаче информации о различиях краудсорс-тестировщикам,[53] чтобы они быстро ее проверяли. Мы хотим оградить наши основные команды разработки и тестирования от лишнего шума. Мы просим внешних помощников посмотреть две версии веб-страницы и обнаруженные различия. Они отмечают, баг это или несущественное отклонение.
Как мы получаем данные от сообщества? Гениальное — просто: мы построили инфраструктуру, которая транслирует необработанные данные ботов на обычную страницу голосования для тестировщиков. Разумеется, мы сравнивали работу краудсорсеров со стандартными методами ручного рецензирования. Схема была следующая: боты пометили только шесть URL-адресов как требующие дополнительной проверки. Помеченные URL-адреса получили тестировщики из сообщества. Имея в арсенале данные ботов и инструменты визуализации различий, краудсорсеры определяли, ошибка ли это, в среднем за 18 секунд. А проверка всех 150 URL-адресов на регрессию ручными методами заняла около трех дней. Тестировщики из сообщества успешно определили все шесть различий как несущественные. Результаты работы краудсорсеров и ручной затратной формы проверки совпали! А зачем платить больше?
Звучит здорово! Правда, этот метод подходит только для статических версий веб-страниц. А как насчет интерактивных элементов — раскрывающихся меню, тестовых полей и кнопок? Мы ведем работу по решению этой проблемы, можно сказать, мы открыли киностудию: боты автоматически взаимодействуют с интересующими нас частями веб-страницы и снимают на каждом шаге кадр DOM. Затем «фильмы» каждой серии сравниваются покадрово с помощью той же технологии анализа различий.
В Google некоторые команды уже заменили большую часть своей ручной работы по регрессионному тестированию ботами. У них появилось время для более интересной работы, например исследовательского тестирования, которой они не могли заниматься раньше. Команда поставила себе цель сделать сервис общедоступным, выложить исходный код для всех и добавить возможности собственного хостинга, чтобы команды могли тестировать внутри своей сети, если кто-то не хочет открывать свои URL-адреса наружу. Мы не торопимся с массовым внедрением новой технологии — нужно убедиться в ее стопроцентной надежности.
Базовый код проекта Bots работает в инфраструктурах Skytap и Amazon EC2. Код сервиса распространяется по модели открытого кода (подробнее в блоге тестирования Google и приложении В). Теджас Шах был техническим руководителем Bots с первых дней существования проекта; позднее к нему присоединились Эриэл Томас, Джо Михаил и Ричард Бустаманте. Присоединяйтесь и вы к этим ребятам, чтобы двигать эксперимент дальше!
Как оценить качество всего интернета
Чтобы измерить, насколько хорошо поисковая система справляется с запросами, для теста мы берем случайную репрезентативную выборку поисковых запросов. По результатам можно судить, как система будет работать со всеми запросами, — мы просто экстраполируем данные. А если мы используем Bots на репрезентативной выборке URL-адресов, мы можем судить о качестве интернета в целом.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Bots: детство, отрочество и масштабирование на весь интернет Теджас Шах
Bots: детство, отрочество и масштабирование на весь интернет Теджас Шах Я — технический руководитель проекта Bots, я хочу масштабировать технологии Bots на весь интернет и открыть их миру. Проект Bots вырос из ранних экспериментов в полноценную технологию, которую используют
Эксперимент BITE
Эксперимент BITE Мы создали BITE (Browser Integrated Test Environment), тестовую среду, интегрированную в браузер, для того чтобы вынести как можно больше тестовых действий, инструментов и данных в браузер и облако и показывать их в контексте. Мы хотели уменьшить время, которое тестировщики
5.1.2. Эксперимент 2
5.1.2. Эксперимент 2 Проделаем теперь еще один эксперимент со второй версией нашей программы. Предположим, мы задаем вопрос:?- f( 7, Y).Y = 4Проанализируем, что произошло. Перед тем, как был получен ответ, система пробовала применить все три правила. Эти попытки породили следующую
Изоляция Кремниевой долины как новый социальный эксперимент в Калифорнии Андрей Васильков
Изоляция Кремниевой долины как новый социальный эксперимент в Калифорнии Андрей Васильков Опубликовано 24 февраля 2014 План выделения Кремниевой долины в отдельный штат перешёл на новый этап. На прошлой неделе эта инициатива получила «зелёный
Голубятня: Толстовский эксперимент или золотая формула успеха Сергей Голубицкий
Голубятня: Толстовский эксперимент или золотая формула успеха Сергей Голубицкий Опубликовано 02 июля 2013 ABBYY сильно напоминает мне самого себя :) В смысле, что компании, как и мне, импонирует роль первопроходца: прийти куда-то первым, выложиться по