3.4.6. Потоки ввода-вывода
3.4.6. Потоки ввода-вывода
Как я уже сказал, каждому процессу сопоставлена таблица открытых им файлов. Три первых позиции в этой таблице заняты всегда: каждый процесс открывает потоки (помните, что в UNIX файл — это и есть поток данных?) для ввода и вывода данных, а также вывода сообщений об ошибках и другой диагностической информации. Эти потоки:
? 0 — стандартный ввод (stdin),
? 1 — стандартный вывод (stdout),
? 2 — стандартный поток сообщений об ошибках (stderr).
Ссылаться на эти потоки можно по их файловым дескрипторам. 0, 1 и 2 — это и есть такие дескрипторы.
По умолчанию потоки ввода-вывода связываются с консолью, с которой запущен процесс: стандартный ввод — с клавиатурой, другие два потока — с экраном (рис. 3.5, потоки cmd1).
Все потоки можно перенаправить в другой файл. Это может быть файл на диске, файл устройства (например, принтер или /dev/null) или стандартный поток другого процесса.
Для перенаправления стандартного вывода команды используется символ > («больше»). Если местом назначения служит файл, то можно его не перезаписывать, а присоединить (append) выводимые данные в его конец. Для такого перенаправления применяется символ >>.
Стандартный ввод перенаправляется символом < («меньше»).
Для перенаправления стандартного потока ошибок используется конструкция 2>. Чтобы присоединить stderr к stdout и перенаправить их вместе, пользуйтесь переадресацией 2>&1.
Для направления стандартного вывода одной команды на стандартный ввод другой применяется символ | — уже знакомый вам конвейер.
Ситуация, изображенная на рис. 3.5, могла бы сложиться после выполнения следующих команд:
cmd2 < file1.txt | cmd3 2>&1 > file2.txt
cmd4 2> /dev/null | tee file3.txt file4.txt file5.txt
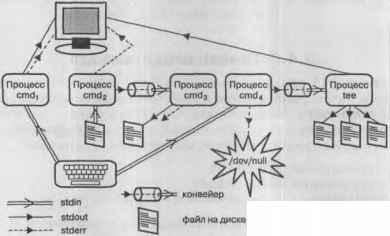
Рис. 3.5. Перенаправление потоков ввода-вывода
Команда-фильтр tee копирует данные со своего стандартного ввода в стандартный вывод, дублируя их при этом в указанные ей файлы.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Планировщики ввода-вывода
Планировщики ввода-вывода Простая отправка запросов на устройство ввода-вывода в том же порядке, в котором эти запросы направляет ядро, приводит к очень плохой производительности. Одна из наиболее медленных операций, которые вообще могут быть в компьютере,— это поиск по
Система ввода-вывода
Система ввода-вывода Ввод-вывод — это Родни Дэнжерфилд[ 76 ] (Rodney Dangerfield) вычислительных систем: на него никто не обращает внимания. Всеобщий любимчик — процессор, а подсистема ввода-вывода рядом с ним — падчерица. Вот пример: когда надо охарактеризовать производительность
Компоненты ввода-вывода
Компоненты ввода-вывода 4 Денис! Эту сноску — на поля! Таблица по старому изданию, сравнить с новым. Для верстальщика: по-моему, стоит убрать рамку — будет красивееТаблица 10.1. Язык ввода-вывода AMQ Очередь свободных сообщений BCT Таблица управления шиной BCU Устройство
Будущее ввода-вывода AS/400
Будущее ввода-вывода AS/400 Высокопроизводительные процессоры для будущих систем AS/400 ничего не дадут, если им не поставлять достаточно данных для полноценной загруженности. Давайте кратко рассмотрим будущее подсистемы ввода-вывода AS/400. Хотя этому вопроса уже уделено
Подсистема ввода/вывода
Подсистема ввода/вывода Подсистема ввода/вывода выполняет запросы файловой подсистемы и подсистемы управления процессами для доступа к периферийным устройствам (дискам, магнитным лентам, терминалам и т.д.). Она обеспечивает необходимую буферизацию данных и
Операции ввода/вывода
Операции ввода/вывода На рис. 4.14 представлена схема выполнения операций ввода/вывода с использованием буферного кэша. Важной особенностью этой подсистемы является то, что она обеспечивает независимое выполнение операций чтения или записи данных процессом как
6.2. Модели ввода-вывода
6.2. Модели ввода-вывода Прежде чем начать описание функций select и poll, мы должны вернуться назад и уяснить основные различия между пятью моделями ввода-вывода, доступными нам в Unix:? блокируемый ввод-вывод;? неблокируемый ввод-вывод;? мультиплексирование ввода-вывода
5.4.1. Потоки ввода-вывода
5.4.1. Потоки ввода-вывода Когда программа запускается на выполнение, в ее распоряжение предоставляются три потока (или канала): • стандартный ввод (standard input или stdin). По этому каналу данные передаются программе; • стандартный вывод (standard output или stdout). По этому каналу
5.2. Перенаправление ввода/вывода
5.2. Перенаправление ввода/вывода Практически все операционные системы обладают механизмом перенаправления ввода/вывода, и Linux не является исключением из этого правила. Обычно программы вводят текстовые данные с консоли (терминала) и выводят данные на консоль. При вводе
19.7.2. Перенаправление ввода/вывода
19.7.2. Перенаправление ввода/вывода Перенаправление ввода/вывода уже рассматривалось в гл. 5, поэтому я лишь напомню общий формат команд:команда > (>>) файлсписок > (>>) файлКак вы уже знаете, при использовании одного знака больше файл, в который переназначен вывод,
Процедуры ввода и вывода
Процедуры ввода и вывода Для ввода исходных данных применяются процедуры READ и READLN. После выполнения процедуры READ значение следующего данного читается из этой же строки, а при выполнении процедуры READLN – с новой строки.READ – читатьНапример: READ (X);READLN – читать с новой
Процедуры ввода и вывода
Процедуры ввода и вывода Стандартная библиотека ввода-вывода языка C подключается с помощью директивы препроцессора #include <stdio. h>Форматный ввод данных пользователя с клавиатуры производится функцией scanf ().scanf (CONTROL, ARG1, ARG2, …);Данная функция осуществляет чтение
Устройство ввода-вывода
Устройство ввода-вывода Вообще говоря, существует много способов ведения диалога человека с ЭВМ, но мы будем предполагать, что вы вводите команды при помощи клавиатуры и читаете ответ на экране
5.6. Стандартные потоки ввода, вывода и ошибок
5.6. Стандартные потоки ввода, вывода и ошибок С каждым процессом (командой, сценарием и т. п.), выполняемым в интерпретаторе shell, связан ряд открытых файлов, из которых процесс может читать свои данные, и в которые он может записывать их. Каждый из этих файлов
Подпрограммы ввода-вывода
Подпрограммы ввода-вывода procedure Read(a,b,...); Вводит значения a,b,... с клавиатуры procedure Readln(a,b,...); Вводит значения a,b,... с клавиатуры и осуществляет переход на следующую строку function ReadInteger: integer; Возвращает значение типа integer, введенное с клавиатуры function ReadReal:
Колисниченко Денис Николаевич
Просмотр ограничен
Смотрите доступные для ознакомления главы 👉