Шаблоны поиска
Еще одну интересную функцию можно считать очень полезной при обработке строковых данных. Она незаменима для анализа, а точнее, парсинга по значительным объемам текста.
Предположим, перед нами – достаточно монотонный текст, состоящий из букв, пунктуации и пробелов. Это может быть html -страница текста, полная рекламы, модулей и ссылок; но небольшая часть этого текста носит важный для нас смысл. Мы хотели бы разметить этот фрагмент текста какими-либо жесткими правилами, однако это невозможно. На начало нужного фрагмента в тексте указывают лишь косвенные признаки, – например, наличие даты, времени публикации и имени автора в следующем формате: «12.08.2018 01:20, АНАТОЛИЙ ИВАНОВ». Строка перед ним – содержит только название статьи, а после и до него – ряды случайных символов.
Эти данные – всегда разные, но формат их записи всегда один. Как нам прочитать их в случайном месте текста?
В этом случае мы используем технологию шаблона. Под шаблоном здесь понимается последовательное использование какого-либо ряда символов (точек, букв, чисел, дефисов и т.п.), которое заранее может быть известно, однако его расположение в строке может быть различным: этот ряд символов может находиться где угодно.
В чем состоит идея:
1. «Прочитать» строку текста, размечая встреченные группы символов одной из нескольких меток. Например, все буквы русского алфавита мы можем пометить «0», пунктуацию – «1», числа – «2», английские буквы – «3», символьные команды и псевдографику «4» и «5», а пробелы – «6». (Согласно этой схеме, упомянутый выше шаблон без имени автора мы могли бы записать как последовательность «22122122226221221»).
2. В «клоне» строки, размеченной полученным кодом мы находим искомый шаблон.
3. Поскольку длина клонированной строки и исходной не отличается, указание на позицию шаблона укажет на позицию первого нужного нам символа в исходной строке и общее количество символов.

Илл. 38. Функция Shablon – определяет наличие в строке шаблона поиска, и возвращает подстроку s2 с указанным в шаблоне фрагментом текста.
Как видно, функция довольно проста, но здесь были использованы некоторые жизненные «лайфхаки». Поскольку бывает довольно сложно проконтролировать всю палитру диапазонов таблицы символов, здесь введена дополнительная переменная логического типа «plus», которая содержит информацию, об использовании очередного символа из строки в шаблоне. Если мы пропустили какой-то символ (if plus=false) после проверки всех полезных для нас вариантов, тогда мы добавляем символ кода «5» в S3 (там может оказаться псевдографика, командные символы и т.п.). В таком случае длина строки, содержащая код шаблона S3 не будет отличаться от исходной S. Также, для того, чтобы каждый раз не проверять код текущего символа из исходника S, мы присвоили его значение переменной j, что ускоряет время исполнения.
По окончании кодирования строки, мы выполняем поиск подстроки SS в полученной строке S3, и копируем фрагмент из реальной строки S с позиции строки полученного шаблона S3 и с длиной подстроки шаблона SS. Фрагмент «S2:=copy (s, pos (ss, s3), length (ss));»
Проверим корректность процедуры:

Илл. 39. Проверка функции shablon в программе.
И вот результат:
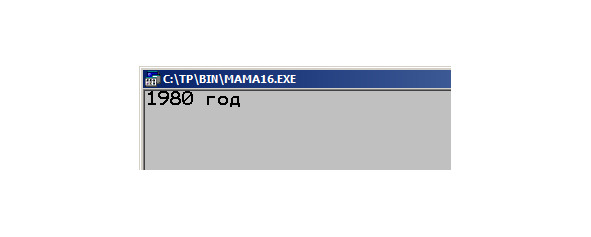
Илл. 40. Результат работы программы с использованием функции shablon.
Функция шаблона с различными модификациями незаменима для парсинга неформализованных данных. К примеру, она подходит для поиска даты рождения, номеров телефонов, домашних адресов, номеров документов, временных периодов трудового стажа и других сведений из текстовых файлов резюме, которые впоследствии могут быть внесены в стандартную форму и нужным образом исправлены.
Но предположим, что пользователь написал дату рождения с лишним пробелом. Например так, 02.12. 1962. Как можно предположить подобную ситуацию и исправить ее автоматически?
Конечно же, во-первых, нам следует убедиться, что имелась ввиду именно дата рождения а не период работы или дата составления резюме. На это могут указывать сопутствующие данные: фрагменты слов в строке с «род», «рожд», «г.р» или «д.р». Убедившись, мы используем ту же функцию shablon, но с некоторой модификацией, которая может получать числовую информацию, игнорируя степень разреженности между числовыми символами.
Так, функция clearshablon в случае необходимости игнорирует наличие или отсутствие в строке дополнительных пробелов, благодаря нескольким операторам, добавленным в функцию shablon и пользуясь описанной выше процедурой insinstring.

Илл. 41. Функция clearshablon – осуществляет поиск шаблона и в случае неудачи пытается улучшить результат, игнорируя символы пробелов.
В итоге, при обработке строки «02.12. 1962» с использованием шаблона, не включающего пробел 2212212222 функция сlearshablon вернет результат «02.12.1962» без лишнего пробела, благодаря синхронным усилиям процедуры insinstring, устранившим все пробелы из строк как в коде-шаблоне, так и в исходной строке.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.