Модель пунктуации
Перейдем к процедуре сохранения пунктуации. Конечно же, она нам очень пригодится. Она очень проста.

Илл. 35. Выделение модели пунктуации из предложения.
Здесь мы берем исходное предложение и (на всякий случай) предварительно исправляем наиболее распространенные ошибки: наличие пробела перед символами пунктуации, с помощью ранее описанной процедуры insinstring. Далее поработаем с элементами массива signs, в котором будем хранить символы пунктуации на время обработки.
Здесь мы начинаем «путешествие» по индексу входного предложения, отмечая каждое слово символом пробела или символом пунктуации, если он есть. Кроме того, мы выделяем весь полученный блок служебными символами «^».
В результате, на строку «Антошка – плохой, нехороший.» мы получим следующую картинку пунктуации « ^-,.^». Что же, теперь мы можем рассматривать любое предложение как набор «чистых» слов и модель пунктуации, к нему прилагающуюся.
Теперь вновь вернемся к задаче, в которой требовалось выделить и обнаружить пару наиболее схожих слов в предложении.
Мы можем использовать следующий алгоритм:
1. Разбить слова в предложении на массив с помощью процедуры justbreak с числом элементов j.
2. Сравним каждое слово массива с каждым и если полученное значение является максимальным, то сохраним его, как ответ. Для этого нам потребуется два цикла и правило, по которому одно и то же слово мы не будем сравнивать с самим собой.
Используя этот нехитрый метод, мы можем получить своего рода игру, в которой программа будет искать слова, близкие по написанию и выбирать их, как на следующем примере:
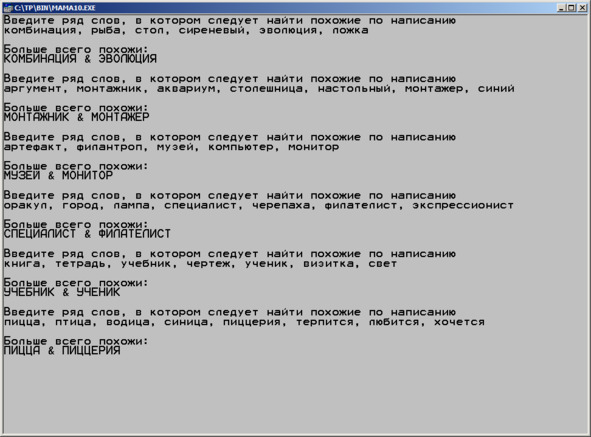
Илл. 36. Тест игры в слова, где из ряда слов, введенных пользователем компьютер выбирает два, наиболее похожих по написанию.
Как видно, программа действует, отсекая символы пунктуации и преобразуя ряд слов из одной строковой переменной в массив слов, а также приводит каждое слово в верхний регистр. Теперь рассмотрим программу, которая осуществляет эти действия.

Илл. 37. Программа «Игры в слова» с компьютером, где из предложенных пользователем слов программа выбирает два наиболее похожих по написанию.
Итак, что мы здесь видим. В первую очередь, это набор строковых переменных (s, s2, s3), которые нужны для обмена данными между процедурами нормализации (decodetodos, getups) и ввода строки пользователем. Также, здесь используются переменные для работы циклов (i и n), для индексирования конца массива sm (j), для определения максимума (max) и текущего состояния баллов (ball). Кроме того – переменные для хранения лучших позиций двух слов (max1) и (max2) в массиве (sm). Массив требуется нам в качестве выходной переменной для использования в описанной выше процедуре justbreak, поэтому мы не производим иных действий с его элементами (по очистке, заполнению пустыми символами и др.), поскольку эти действия уже прописаны в самой процедуре justbreak.
Весь алгоритм кроме исходных функций очистки мы поместили в цикл Repeat с отсутствием условия выхода (Until false) для того, чтобы вопросы и ответы повторялись при желании пользователя бесконечно.
После нормализации (декодирования) приветственной фразы «Введите ряд слов, в котором следует найти похожие по написанию» и выведении ее на экран, от пользователя получается строка S, в которой он написал ряд слов. Эту строку мы разбиваем процедурой justbreak на массив слов sm с известным числом элементов j, после чего в двух циклах последовательно сравниваем (с помощью percentcheck2) различные элементы массива друг с другом, если речь не идет об одном и том же элементе (i <> n). Если текущий максимум Max оказывается ниже текущей оценки Ball, мы передаем число Ball в Max, и запоминаем позиции I и N, сохраняя их в переменные max1 и max2 соответственно. После окончания циклов сравнения мы выводим результат из массива sm с индексами max1 и max2 и ждем следующее задание.
Эта игра может быть усовершенствована. Например, в роли задающего вопрос и генерирующего слова мы можем поставить программу, а человек будет их угадывать. Но для этого нам уже потребуется работа со словарями, чем мы и займемся позже.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.