Преобразования строк
Str (N, S); – преобразует число N в строку S.
Иногда это требуется для операций над числовыми данными, например, для преобразования даты и времени в наборы символов строкового типа. Дело в том, что в Паскале мы не можем смешивать данные разных типов, и для этого требуется привести их к одному типу.
Для наглядности, рассмотрим процедуру, которая генерирует строку информации о завтрашней дате в читаемом формате. Результат должен выглядеть, допустим, так: «1 марта 2019 года». Все что у нас есть, это информация о дате сегодняшней, полученной посредством оператора GetDate. Эта информация кажется банальной, но в ней мы должны учесть в случае необходимости, содержит ли текущий месяц 30 или 31 день. Также стоит знать, является ли год високосным, если сегодня 28 февраля; стало быть завтрашний день может быть как первым днем календарной весны, так и 29 февраля. Как осуществить этот выбор?
Оператор Str здесь используется дважды в конце: для преобразования числа года и дня и последующей их конкатенации (иначе говоря, объединения) в одной строке.

Илл. 27. Листинг процедуры Gettomorrow, получающей точную завтрашнюю дату в формате строки.
Что происходит? В качестве выходной переменной процедуры мы указали единственную переменную S, в которую будет необходимо отправить результат – строку с датой. Далее, внутренними переменными мы описали Year (год), Month (месяц), Day (день) и Day_of_week (день недели); а также их строковые версии: Years, Months, Days. (Поскольку день недели в данном случае нам не интересен, мы не будем заниматься его описанием и преобразованием).
Первоначально, получив из операционной системы информацию о дате в формате чисел «GetDate (year, month, day, day_of_week)», мы прибавляем к числовому значению дня единицу «Inc (day)», и смотрим, что из этого получится.
В операторе сравнения с перечислением «Case» мы выбираем варианты сценариев. В месяце однозначно не может быть 32 дня, поэтому сталкиваясь с этим числом, мы присваиваем переменной дня единицу и увеличиваем значение месяца на единицу. Но если на дворе был декабрь? Мы помним об этом, и если это так (числовое значение месяца «Month» превратилось в 13), то прибавляем к году единицу «Inc (year)», если сегодня 31 декабря.
Но как мы помним – 31-ый день бывает не в каждом месяце; поэтому мы включаем в исключения и 31-ые числа ноября, сентября, июня и апреля, – если таковые получились, то значение месяца «Month» так же увеличиваем на единицу, а значению дня «Day» присваиваем 1.
Число 30 невозможно даже после крайне редкого дня «29 февраля», поэтому мы предусматриваем и его в виде исключения.
И наконец, 29 февраля бывает не в каждом месяце. Поэтому если мы встречаем такой вариант, нам необходимо уточнить, является ли год високосным или нет.
Точное определение високосного года звучит так:
«Год високосный, если он делится на четыре без остатка, но если он делится на 100 без остатка, это не високосный год. Однако, если он делится без остатка на 400, это високосный год.»
То есть, в данном случае, если мы видим попадание в одно из условий, когда год не делится на 4 без остатка, либо когда делится на 100, но не делится на 400, то считаем этот год обычным и следующим днем считается 1 марта.
Затем мы присваиваем в очередном блоке сравнений case значение месяцев в нужном нам склонении: «января», «февраля» и так далее. И наконец, в результате преобразований числовых данных в строковые, получаем итоговый, нужный результат.
Теперь мы рассмотрим обратную процедуру Val (S, N, R), где происходит преобразование S – строки, в N – число, с сообщении об ошибке (или ее отсутствие) в R.
Ниже приведен фрагмент программы в которой число, записанное в строковой переменной S преобразуется в N. Результат операции R при этом сообщит нам, есть ли в преобразовании ошибка (код R <> 0) или ошибка отсутствует (R=0).

Илл. 28. Пример использования процедуры преобразования строки S в число N с результатом преобразования R, с помощью процедуры Val.
Теперь мы рассмотрим процедуру для преобразования фрагмента текста с использованием дополнительной информации. Предположим, мы имеем текст статьи, который необходимо дополнить некоторыми строковыми данными. В статье может встретиться употребление информации о процентах, которое мы должны расширить, например, «95%» заменить на фразу «почти все (95%)». Также при встрече дробного процентного показателя, процедура должна округлить его, например «19,2%» употребить «менее пятой части (19%)». Вариативность такого «очеловечивания» процентных показателей может быть достаточно широкой (в приведенном примере, до 24 вариантов).
Что нам потребуется для упрощения этой задачи. Во-первых, это функция определения символов цифр Trycifra.

Илл. 29. Функция trycifra проверяет символ на принадлежность к цифрам от 0 до 9.
Во-вторых, это уже описанная ранее процедура InsInString. И в-третьих, это файл, «DictPer. txt», который необходимо сохранить в рабочем каталоге программы (по умолчанию это C:/TP/BIN). Он будет содержать числовые диапазоны значений и их описания (кодировка Win). Приведем его содержимое полностью:
«0
3
незначительный процент
3
5
менее двадцатой части
5
8
чуть более двадцатой части
8
10
менее десятой части
10
15
более чем десятая часть
15
16
менее шестой части
16
19
менее пятой части
19
21
пятая часть
21
25
больше пятой части
25
25
четверть
26
27
более чем четверть
27
30
почти третья часть
30
40
более чем третья часть
40
50
менее половины
50
58
более половины
59
65
около двух третей
65
75
почти три четверти
75
77
три четверти
77
80
почти четыре пятых
80
82
четыре пятых
82
92
подавляющее большинство
92
100
почти все
100
100
все
100
10000000
более 100%»
Теперь приступим к сборке и рассмотрим происходящее подробнее.
В процедуре нам потребовалось много строковых переменных для текущих операций (S-S8), две переменные для хранения диапазона (N2 и N3), одна – для текущего показателя (N типа Real), одна – символьного типа (C), одна переменная для связи файла (F типа Text), и две – логического типа (Boolean) для контроля над текущим состоянием операции (b и tryfalse).

Илл.30. Процедура LogicPercent, дополняющая числовые данные процентов различными фразеологизмами.
На вход в процедуру мы имеем строку S, к обработке которой приступаем в случае нахождения в ней символа «%». В цикле меняется значение текущего символа S [i], и если мы встречаем обычные буквы или иные символы, то устанавливаем текущее значение tryfalse=true.
Если же нам встречается число или символы дроби, то мы храним его в переменной S3, поскольку оно может оказаться, а может и не оказаться процентом. Логический указатель числа («нужного» символа) устанавливаем на B=true, и отменяем значение «ненужного» символа TryFalse=false. Также мы дублируем это значение в переменной S8.
Встретив символ процента, цикл завершается. Мы преобразуем значение строковой переменной S3 в число N. Результат преобразования j мы игнорируем, поскольку контролировали код символов и уверены в числовом содержимом переменной. Поэтому используем в дальнейшем j как хранилище для округленного значения N (Round (N)).
Затем мы открываем файл словаря значений DictPer. txt, читаем его по 3 строки сразу, причем первые два «читаем» как числа (N2 и N3) с которыми сравниваем текущее число значения j. Если число j попадает в промежуток между указанными числами, нами используется символьное выражение из файла s6, которое мы не забываем переводить в кодировку DOS (процедура decodetodos).
Теперь протестируем готовую процедуру в следующей программе.
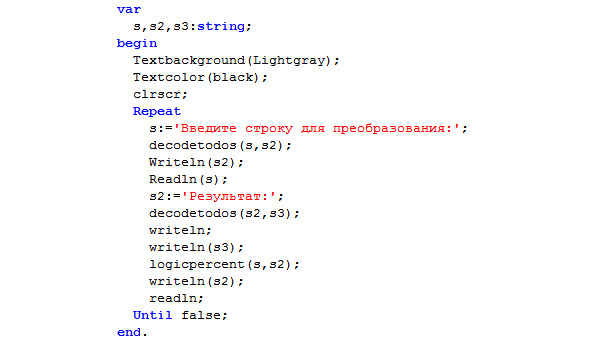
Илл. 31. Программа для тестирования процедуры LogicPercent.
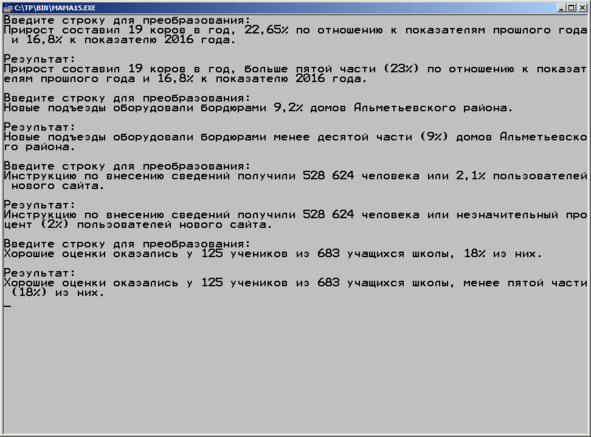
Илл. 32. Пример работы процедуры LogicPercent.
По такому принципу можно обрабатывать большие массивы текста, добиваясь, к примеру, увеличения его уникальности.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Сергей Соболенко
Просмотр ограничен
Смотрите доступные для ознакомления главы 👉